Subscribe to RSS
DOI: 10.1055/a-1167-8402
KI in der Radiologie: Wo stehen wir in der MS-Bildgebung?
Article in several languages: English | deutschAuthors

Zusammenfassung
Hintergrund MRT-Untersuchungen sind ein zentraler Baustein in der Diagnostik bei Multipler Sklerose (MS). Dies gilt sowohl für das Erstereignis wie auch für die Verlaufsbeurteilung. In den vergangenen Jahren wurden zunehmend Algorithmen zur Analyse von MRT-Daten bei MS entwickelt. Diese Übersichtsarbeit stellt die wesentlichen Anwendungsfelder unter besonderer Berücksichtigung von Algorithmen aus dem Bereich der Künstlichen Intelligenz (KI) vor.
Methoden Relevante Studien wurden durch eine Literatursuche in anerkannten Datenbanken sowie durch Querverweise in so gefundenen Studien identifiziert. Dabei wurde Literatur berücksichtigt, die bis November 2019 erschienen war, ein besonderes Augenmerk lag auf kürzlich erschienenen Studien aus den Jahren 2018 und 2019.
Ergebnisse Viele Studien haben Lösungen zur optimierten Läsionsvisualisierung oder der Segmentierung von Läsionen entwickelt. Hier liegen bereits Werkzeuge vor, die diese Aufgaben mit hoher Genauigkeit bewerkstelligen können und damit mittelbar eine reproduzierbare, quantitative Auswertung der Läsionslast ermöglichen. Einige Arbeiten gingen einem Radiomics-Ansatz nach und untersuchten die Vorhersage klinischer Endpunkte, z. B. die Konversion von einem klinisch isolierten Syndrom zu definitiver MS. Zuletzt liegen erste Arbeiten vor, die synthetisch erstellte Bildgebung untersuchen, also solche Bilder, die basierend auf tatsächlich gemessenen MRT-Sequenzen von Maschinenlernalgorithmen generiert werden und die Kontraste zwischen Läsionen und normalem Hirnparenchym optimieren.
Schlussfolgerung Computerunterstützte Bildanalyse und KI sind hochaktuelle Themen in der MS-Bildgebung. Einzelne Anwendungen sind dabei bereits jetzt prinzipiell in der klinischen Routine einsetzbar. Eine wesentliche Herausforderung für die Zukunft besteht vor allem darin, bessere Prädiktionen klinischer Verläufe und entsprechende Hilfestellungen in der Findung einer optimalen Therapie auf patientenindividueller Ebene bereitzustellen. Außerdem rücken durch die Erfolge auf technologischer Ebene zunehmend Fragen über die Integration in klinisch-radiologische Abläufe in den Vordergrund.
Kernaussagen:
-
Computeralgorithmen haben einen zunehmenden Einfluss auf die Auswertung von MRT-Bildgebung bei Multipler Sklerose.
-
Künstliche Intelligenz wird zunehmend für solche Algorithmen verwendet.
-
Wesentliche Anwendungen sind die Läsionssegmentierung, die Prädiktion klinischer Parameter sowie die Generierung synthetischer Bildgebung.
Zitierweise
-
Eichinger P, Zimmer C, Wiestler B. AI in Radiology: Where are we today in Multiple Sclerosis Imaging?. Fortschr Röntgenstr 2020; 192: 847 – 853
Einleitung
Multiple Sklerose (MS) ist eine neurologische Erkrankung, die insbesondere in frühen Krankheitsphasen bei vielen Betroffenen durch autoimmun-vermittelte Schubereignisse gekennzeichnet ist [1]. In MRT-Untersuchungen zeigen sich entsprechende Parenchymläsionen des zentralen Nervensystems. Dies bedingt zum einen eine wesentliche Rolle der Bildgebung in der Diagnosestellung gemäß den aktuellen McDonald-Kriterien [2], zum anderen lässt sich über die Darstellung entzündlicher Läsionen die Krankheitsaktivität im Verlauf beobachten. Neben der Läsionsdiagnostik werden zunehmend auch weitere MRT-Parameter wie Atrophieraten [3] zur Charakterisierung des Krankheitsverlaufs genutzt. Entsprechend haben sich MRT-Untersuchungen als wichtiges Werkzeug etabliert, um die Wirksamkeit einer immunmodulatorischen Therapie zu überwachen: Eine bildgebend nachgewiesene Krankheitsaktivität eröffnet die Möglichkeit einer Therapieumstellung noch vor einer klinisch fassbaren Verschlechterung [4].
Die Auswertung von MRT-Bildgebung bei MS ist daher eine sehr häufige Aufgabe in der (neuro-) radiologischen Routine. Die für die Überwachung des Krankheitsverlaufs relevanten Fragen sind klar definiert (Wie hat sich die Läsionslast entwickelt? Gibt es Zeichen einer zunehmenden Atrophie?) und entsprechend in den NEDA-Kriterien (No Evidence of Disease Activity) kodifiziert [3]. Durch diese Standardisierung sowie durch die hohe Zahl an erhobenen MRT-Datensätzen gehört die MS zu den Krankheitsbildern, bei denen die computergestützte Auswertung der Bildgebung an Bedeutung gewinnt. Mit zunehmender Popularität von sogenanntem Deep Learning [5] und einem allgemein wachsenden Interesse an Künstlicher Intelligenz (KI) wurde diese Entwicklung weiter beschleunigt
Ziel dieser Arbeit ist es, einen Überblick über kürzlich publizierte Anwendungsbeispiele von Computeralgorithmen im Kontext von MS-Bildgebung bereitzustellen. Dabei liegt ein Hauptaugenmerk auf Studien aus dem Feld der KI [6].
Technischer Hintergrund
Bei konventionellen CAD-Anwendungen (Computer aided diagnosis) wird ein Algorithmus explizit mit Expertenwissen programmiert, um ein bestimmtes Problem zu lösen. Demgegenüber wird beim Maschinenlernen zwar eine grobe Architektur des Algorithmus vorgegeben, die genaue Ausgestaltung wird aber von diesem „erlernt“. Hierzu sind Trainingsdaten notwendig, anhand derer die Parameter des Algorithmus schrittweise eingestellt („gelernt“) werden. Im Rahmen dieses Übersichtsartikels sind insbesondere 3 Arten von Maschinenlernalgorithmen von Bedeutung: Support-Vector-Maschinen, Random-Forest-Modelle und künstliche neuronale Netzwerke.
Support-Vector-Maschinen (SVM) sind auf Klassifikationsprobleme hin ausgerichtet, daneben lassen sie sich auch für Regressionsaufgaben verwenden [7]. Hierfür werden die Trainingsdaten als Punkte in einem Datenraum aufgefasst. Im einfachsten Fall wäre das eine Ebene, also ein xy-Diagramm. Für dieses Beispiel wird dann eine Gerade berechnet, die diese Datenpunkte gemäß ihrer Klasse voneinander trennt. Im Allgemeinen, wo die Daten als komplexer Vektor vorliegen, wird entsprechend ein höherdimensionales Analogon einer solchen Trennungsgerade berechnet.
Bei Random-Forest-Modellen [8] wird eine Gruppe von unkorrelierten Entscheidungsbäumen erzeugt, deren gemeinsames Votum das Ergebnis bestimmt. Mit dieser Architektur sind solche Algorithmen ebenfalls auf Klassifikationsprobleme zugeschnitten, können aber auch Regressionsprobleme lösen.
Künstliche neuronale Netze sind mehrlagige Vernetzungen von künstlichen Neuronen. Diese ähneln ihren biologischen Vorbildern nur entfernt. Letztlich beinhalten sie nur eine Vorschrift, wie aus mehreren Eingängen eine Ausgabe generiert wird. Die im Lernprozess anzupassenden Parameter innerhalb eines neuronalen Netzwerks sind die Verbindungsstärken zwischen den einzelnen Neuronen. Der aktuell häufig verwendete Begriff „Deep Learning“ bezieht sich auf solche künstlichen neuronalen Netzwerke, die über wenige Einzelschichten hinausgehen. Allerdings ist dieser Begriff nicht streng definiert [9]. Ein wesentlicher Unterschied zwischen SVM und Random-Forest-Modellen auf der einen Seite und künstlichen neuronalen Netzwerken auf der anderen Seite ist, dass bei den erstgenannten Modellen die Features (also in quantitative Werte übersetzte Bildeigenschaften), auf denen die Algorithmen basieren, zuvor vorgegeben werden. Künstliche neuronale Netzwerke sind hingegen nicht auf vordefinierte Features festgelegt, sondern „erlernen“ relevante Bildeigenschaften selbstständig im Trainingsprozess.
Literatursuche
Die im Rahmen dieser Übersichtsarbeit berücksichtigten Arbeiten wurden über eine Literatursuche mittels PubMed (https://www.ncbi.nlm.nih.gov/pubmed/) identifiziert. Dabei wurden Artikel herangezogen, die bis zum 30. November 2019 erschienen waren. Besonderes Augenmerk wurde auf aktuelle Studien aus den Jahren 2018 und 2019 gelegt. Die Begriffe, die im Rahmen der Recherche genutzt wurden, waren „Multiple Sclerosis“ und „MRI“ bzw. „Neuroimaging“, jeweils in Verbindung mit „Artificial Intelligence“, „Machine Learning“ und „Neural Networks“. Des Weiteren wurden die Literaturverzeichnisse der so gefundenen Artikel auf weitere passende Titel hin durchsucht.
Literaturergebnisse: Anwendung von KI bei Multipler Sklerose
Läsionsdetektion und -segmentierung
Die manuelle Analyse von Läsionsdaten hinsichtlich neuer oder vergrößerter Läsionen, eine der radiologischen Kernaufgaben in der Auswertung von MS-Bildgebung, ist aufwendig und fehleranfällig. Demgegenüber bietet eine automatische Segmentierung die Möglichkeit, objektive Parameter, wie z. B. Läsionsvolumina, direkt zu erfassen. Daher befassen sich viele Studien damit, diese Läsionen entweder besser zu visualisieren oder sogar direkt zu segmentieren. Eine Strategie zum Vergleich zweier Untersuchungen ist die Generierung von Subtraktionskarten [10] [11]. Hierzu werden die beiden zu vergleichenden MRT-Sequenzen koregistriert und anschließend die Intensitätswerte voxelweise voneinander abgezogen. Angewandt auf den Vergleich einer Verlaufs-MRT mit einer Referenzuntersuchung lassen sich so Karten erzeugen, die neu aufgetretene Läsionen direkt visualisieren ([Abb. 1]). Mit dieser Technik kann einerseits die Sensitivität in der Detektion neuer Läsionen deutlich erhöht werden, andererseits wird die Zeit, die zum Vergleich der beiden Untersuchungen benötigt wird, bis um den Faktor 3 reduziert [11]. Subtraktionskarten, als Beispiel konventioneller Tools, demonstrieren, dass bereits verhältnismäßig einfache Computeralgorithmen den radiologischen Alltag erheblich unterstützen können. In Projekten, die unmittelbar auf dieser Technologie basieren, konnte gezeigt werden, dass eine Kontrastmittelgabe nicht mehr zu einer weiteren Sensitivitätssteigerung in der Detektion neu aufgetretener Läsionen im Verlauf beitragen kann [12]. Außerdem wurden Subtraktionskarten verwendet, um die Gleichwertigkeit einer neuartig beschleunigten Double-Inversion-Recovery (DIR) -Sequenz mit einer konventionell akquirierten DIR-Sequenz zu zeigen [13].

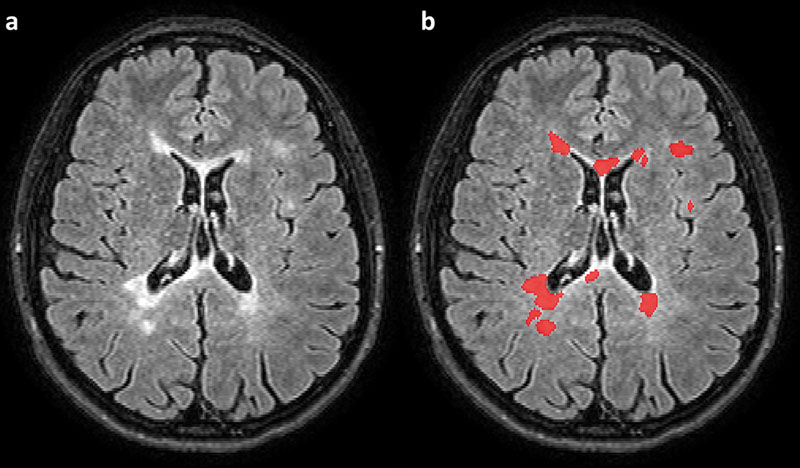
Die Aufgabe der Läsionssegmentierung wird bereits seit vielen Jahren mittels verschiedener Techniken bearbeitet, eine Zusammenstellung über frühere Publikationen findet sich z. B. bei Schmidt et al. [14]. In dieser Arbeit wurde ebenfalls ein eigenes Tool zur Segmentierung von MS-Läsionen vorgestellt. Dieses, wie auch die dort aufgeführten Arbeiten, fußen auf konventionellen Programmiermethoden. Eine neuere Übersichtsarbeit, die sich speziell dem Thema Läsionssegmentierung widmet und auch KI-Studien berücksichtigt, legten Danelakis et al. vor [15]. Ein Beispiel einer solchen aktuellen Studie stammt von Li et al. [16]. Diese basiert auf einem sogenannten U-Net [17]. Dies ist eine bestimmte Art eines Deep-Learning-Netzwerks, die sich als besonders leistungsfähig für Segmentierungsaufgaben erwiesen hat. Die Arbeit von Li et al. widmet sich der Segmentierung von Hyperintensitäten der weißen Substanz im Zusammenhang mit zerebraler Mikroangiopathie. Da die Segmentierung von mikroangiopathischen Läsionen und von MS-Läsionen sehr ähnliche Aufgaben sind, lässt sich dieser Algorithmus bei angepassten Trainingsdaten auch auf MRT-Untersuchungen bei MS anwenden. Ein Beispiel einer so gewonnenen Segmentierung zeigt [Abb. 2]. Eine kürzlich erschienene Arbeit von Gabr et al. [18] nutzte ebenfalls ein U-Net zur Segmentierung von MS-Datensätzen. Das Besondere an dieser Arbeit ist das große Kollektiv von über 1000 MRT-Untersuchungen, die aus einer multizentrischen Phase-III-Studie stammen. Außerdem wird in dieser Arbeit auch die Segmentierung des Hirnvolumens mittels eines U-Nets vorgestellt, wodurch auch Atrophieraten automatisiert bestimmt werden können.

Integration klinischer Daten
Die bislang beschriebenen Verfahren sind bildgebungsimmanenten Fragestellungen gewidmet. Viele Studien verfolgen demgegenüber aber auch das Ziel, mithilfe von Maschinenlernverfahren Informationen in Bilddaten zu erfassen, die einer radiologisch-visuellen Auswertung nicht unmittelbar zugänglich sind und so die Beantwortung neuer Fragestellungen ermöglichen [19]. MRT-Bildgebung kann dazu beitragen, sehr früh (je nach Konstellation bereits zum Erstereignis) eine verlässliche Diagnose zu treffen [2]. Dennoch gibt es häufig die Situation, dass zwar ein klinisches Ereignis als möglicher erster Schub einer MS angesehen wird, sich jedoch noch keine definitive Diagnose stellen lässt. Diese Konstellation wird als klinisch isoliertes Syndrom (KIS) bezeichnet [20]. Häufig geht ein solches KIS in eine definitive MS über [21]. Patienten mit einem hohen Konversionsrisiko sollten zumindest engmaschig überwacht und gegebenenfalls auch schon sehr frühzeitig immunmodulatorisch behandelt werden [22] [23]. Daher ist die Vorhersage des individuellen Konversionsrisikos klinisch hochrelevant. In mehreren Studien wurde untersucht, ob sich mithilfe von KI-Verfahren bereits anhand der initialen Bildgebung bei KIS-Patienten die spätere Konversion oder Nichtkonversion vorhersagen lässt. Zhang et al. [24] nutzten hierzu ein Random-Forest-Modell, das auf Helligkeits- und Form-Features der Läsionen in der initialen MRT-Untersuchung basiert. Dabei trugen nur Form-Eigenschaften der Läsionen zu einer Verbesserung der Prädiktion bei, insbesondere solche, die direkt oder indirekt die Ovalität der Läsionen beschreiben. Auf der Intensitätsverteilung der Läsionen basierende Features konnten die Vorhersagegenauigkeit hingegen nicht verbessern. Berndfeldt et al. [25] untersuchten die gleiche Fragestellung mithilfe eines SVM-Verfahrens, wobei neben der Läsionsgeometrie auch klinische und demografische Daten sowie Angaben zum Volumen der grauen Substanz miteinbezogen wurden. Auch diese Arbeit zeigte einen wesentlichen Beitrag der Läsionsgeometrie zur Klassifikationsgenauigkeit. Diese Ergebnisse spiegeln wider, dass MS-Läsionen häufig ovoid erscheinen („Dawson-Finger“). Damit korreliert die Entscheidungsfindung dieser Werkzeuge mit bereits bekannten Läsionseigenschaften, wodurch das Verhalten der Algorithmen transparent nachvollziehbar wird.
Andere bereits bearbeitete Fragestellungen für Radiomics-Arbeiten waren die Differenzierung von MS und Erkrankungen aus dem Neuromyelitis-Optica-Spektrum [28] [29] [30] und die Abgrenzung von MS-Patienten von gesunden Kontrollprobanden. Zum letztgenannten Thema existieren auch auf Deep Learning beruhende Studien [31] [32] [33]. Eitel et al. [34] untersuchten hierbei auch, welche Merkmale der Algorithmus zur Klassifikation heranzieht, und konnten so zeigen, dass neben den typischen Läsionen in geringerem Maß auch normal erscheinende Areale, wie z. B. die Thalami, zur Entscheidung des Algorithmus beitragen können. Auch in anderen Studien wie von Weygandt et al. [35] und Yoo et al. [31] konnte ein Beitrag gesund erscheinender Bereiche zur Vorhersage des Algorithmus gefunden werden. Eine frühere, auf einem SVM-Verfahren basierende Studie von Hackmack et al. [36] untersuchte den Nutzen sehr komplexer und damit abstrakter Features, die durch sog. Wavelet-Transformationen gewonnen werden. Diese Ergebnisse belegen eindrucksvoll, dass KI-Bilddaten auch jenseits der visuell-radiologisch interpretierbaren Informationen nutzbar gemacht werden können. In einer anderen Studie konnten Hackmack et al. eine Korrelation der räumlichen Information von MRT-Untersuchungen zur Symptomausprägung bei MS-Patienten zeigen [37]. Die visuell-radiologische Auswertung von MS-Läsionen steht hingegen vor dem sog. „kliniko-radiologischen Paradox“, nämlich der Erfahrung, dass Läsionslast und -verteilung, so wie sie konventionell erfasst wird, keine Aussage über die Krankheitsschwere zulässt.
Synthetische Bilderzeugung
Eine neuere Anwendung Künstlicher Intelligenz ist die Erzeugung synthetischer Sequenzen, die mittels neuronaler Netzwerke anhand bestehender Bildgebung vorhergesagt werden [38]. Finck et al. nutzten einen solchen Ansatz, um eine Double-Inversion-Recovery-Sequenz (DIR) aus einer FLAIR- (FLuid Attenuated Inversion Recovery), einer T2-gewichteten und einer T1-gewichteten Sequenz zu generieren [39]. DIR-Sequenzen zeigen einen besonders hohen Läsion-zu-Parenchym-Kontrast und stellen kortikale Läsionen besser dar, als konventionelle Sequenzen [40] [41] [42]. Nachteile der DIR-Sequenz sind ein hoher technischer Aufwand und eine gewisse Artefaktanfälligkeit, sodass sie mit Ausnahme weniger Zentren keinen Eingang in Routine-MRT-Protokolle gefunden hat. Eine synthetische Generierung aus Standardsequenzen könnte diese Nachteile umgehen und damit DIR-Sequenzen zu einer größeren Verbreitung verhelfen. In der genannten Studie zeigte sich, dass die synthetische Sequenz zwar etwas hinter der real akquirierten DIR-Sequenz zurückblieb, jedoch signifikant besser MS-Läsionen darstellte als die (real akquirierte) FLAIR-Sequenz. In einer Art „Turing-Test“ waren Neuroradiologen nicht in der Lage, zwischen einer real akquirierten und einer synthetischen DIR-Sequenz zu unterscheiden [38]. [Abb. 3] zeigt ein Beispiel einer synthetischen DIR-Sequenz.

Diskussion und Ausblick
Die Anwendung von KI bei MS wird durch mehrere Punkte begünstigt: MS ist eine häufige Erkrankung und Betroffene erhalten regelmäßige MRT-Untersuchung. Daher werden insbesondere an Zentren große Zahlen an MRT-Untersuchungen durchgeführt. Eine ausreichende Anzahl an Datensätzen ist aber für Maschinenlernen unerlässlich, um ein effektives Lernen zu gewährleisten. So ist es nicht verwunderlich, dass zwar für die Läsionsdiagnostik eine Vielzahl an Arbeiten existiert, jedoch keine für die Erkennung von relativ seltenen Therapiekomplikationen wie PML (progressive multifokale Leukenzephalopathie).
Dabei kann die Bereitstellung eines großen Datensatzes die Entwicklung Künstlicher Intelligenz maßgeblich beeinflussen: Besonders prominent ist hier die Alzheimers-Disease-Neuroimaging-Initiative (ADNI), auf deren Datenbank eine Vielzahl von Maschinenlernstudien zu degenerativen Erkrankungen basiert.
Von den vorstehenden Themen ist die Läsionssegmentierung das am intensivsten untersuchte. Hier sind die eingesetzten Algorithmen weit gereift, teilweise sogar als kommerzielles Produkt CE-zertifiziert bzw. von der FDA zugelassen. Damit stehen Tools zur Verfügung, die prinzipiell bereits jetzt den radiologischen Alltag unterstützen können. Die Ergebnisse dieser Techniken lassen sich außerdem in strukturierte Befunde [43] einbinden, sodass ein weitgehend automatisierter Workflow zur standardisierten Analyse der MRT-Läsionslast technisch unmittelbar greifbar erscheint.
Die Prädiktion klinischer Parameter ist hingegen noch nicht so weit fortgeschritten. Eine wichtige Aufgabenstellung für künftige Computeralgorithmen wäre etwa die Prädiktion klinischer Verläufe. Die oben erwähnten Studien zur Vorhersage der Konversion bei KIS-Patienten können hierfür als ein erster Schritt gesehen werden. Auch die erwähnte Studie von Hackmack et al. zur besseren Korrelation von Bildgebung und klinischer Krankheitsausprägung zeigt eine vielversprechende Anwendungsrichtung, die durch Computeralgorithmen eröffnet wird.
Ein früher Therapiebeginn gilt bei MS als besonders wichtig [44] [45], daher könnte eine zuverlässige frühe Vorhersage des zu erwartenden Verlaufs Therapieentscheidungen beeinflussen. Angesichts eines immer breiter werdenden Arsenals an verfügbaren Medikamenten [46] wäre es außerdem besonders interessant, inwiefern Maschinenlernen dazu beitragen kann, für einzelne Patientinnen und Patienten die jeweils individuell am besten geeignete Therapie zu identifizieren. Spätestens hier erscheint es aber auch zunehmend unwahrscheinlich, dass diese Aufgabe von Algorithmen gelöst werden kann, die allein auf Bildgebung beruhen. Vielmehr werden für derartige Fragestellungen zunehmend klinische Daten als weitere Eingabeparameter in einen Algorithmus integriert werden müssen. Bei der Interpretation von KI-Studien ist von besonderer Bedeutung, dass die Qualität eines Algorithmus maßgeblich von der Lernkohorte abhängt. Hier ist klinische Expertise insbesondere bezüglich der Qualität der Label nötig. Beispielsweise beziehen sich mehrere der oben vorgestellten Projekte noch auf die McDonald-Kriterien in der Fassung von 2010. Würde man hingegen die aktualisierte Fassung (2017) als Label heranziehen, würden einige zuvor mit einem KIS diagnostizierte Patienten bereits zum Baseline-Zeitpunkt als definitive MS gewertet werden (insbesondere aufgrund der Einbeziehung der Liquordiagnostik). Diese Algorithmen können damit nicht problemlos zur Prädiktion entsprechend der aktuellen McDonald-Kriterien herangezogen werden.
Mit der Generierung von DIR-Sequenzen wurde ein Beispiel vorgestellt, wie synthetische Bildgebung genutzt werden kann, um real akquirierte Daten effizient zu nutzen. MRT-Protokolle weisen hinsichtlich der Darstellung von MS-Läsionen insofern eine gewisse Redundanz auf, als Läsionen in der Regel in mehreren Sequenzen dargestellt werden. Hier wäre es ein wichtiger Anknüpfungspunkt zu untersuchen, wie ein „minimales“ MRT-Protokoll aussehen könnte, also ein möglichst kleiner Satz an Sequenzen, aus dem dann andere Bildkontraste synthetisch generiert werden könnten.
In den letzten Jahren ist der Nutzen von Kontrastmittel in der MS-Bildgebung hinsichtlich einer möglichst hohen Sensitivität bei der Läsionsdetektion infrage gestellt worden [12] [47]. Gleichzeitig lässt die Diskussion um intrakranielle Gadoliniumablagerungen [48] viele Patientinnen und Patienten zunehmend skeptischer gegenüber dem Einsatz von Kontrastmittel werden. Es gibt bereits einige Studien, die die Unterscheidung von kontrastmittelanreichernden und nichtanreichernden Läsionen mittels anderer MRT-Parameter (z. B. Diffusionsbildgebung) untersucht haben [49]. In diesem Kontext erscheint es als ein besonders interessantes Ziel, eine T1-gewichtete Sequenz nach Kontrastmittelgabe basierend auf nativer Bildgebung zu synthetisieren. Eine derartige Studie wurde kürzlich von Kleesiek et al. für Gliome vorgestellt [50].
Zusammenfassend lassen sich im Zusammenhang mit MS viele Anwendungsbeispiele von KI in der Verarbeitung von Bildgebungsdaten identifizieren. Für Segmentierungsaufgaben gibt es Lösungen, die bereits jetzt im radiologischen Alltag verfügbar wären. Damit rücken neben den fachlichen auch zunehmend praktische Aspekte in den Vordergrund. Hierzu gehört vornehmlich die Einbindung entsprechender Software in bestehende IT-Infrastrukturen sowie der Zugang zu notwendiger Rechenkapazität. Da außerdem wohl nur kommerzielle Produkte eine Zertifizierung zur Verwendung im klinischen Alltag erreichen können, wird auch die Frage nach der Finanzierung solcher Programme einen wesentlichen Einfluss auf ihre tatsächliche Verbreitung haben.
Conflict of Interest
The authors declare that they have no conflict of interest.
-
References
- 1 Thompson AJ, Baranzini SE, Geurts J. et al. Multiple sclerosis. Lancet 2018; 391: 1622-1636
- 2 Thompson AJ, Banwell BL, Barkhof F. et al. Diagnosis of multiple sclerosis: 2017 revisions of the McDonald criteria. Lancet Neurol 2018; 17: 162-173
- 3 Kappos L, De Stefano N, Freedman MS. et al. Inclusion of brain volume loss in a revised measure of “no evidence of disease activity” (NEDA-4) in relapsing-remitting multiple sclerosis. Mult Scler 2016; 22: 1297-1305
- 4 Cortese R, Collorone S, Ciccarelli O. et al. Advances in brain imaging in multiple sclerosis. Ther Adv Neurol Disord 2019; 12
- 5 Lecun Y, Bengio Y, Hinton G. Deep learning. Nature 2015; 521: 436-444
- 6 Hosny A, Parmar C, Quackenbush J. et al. Artificial intelligence in radiology. Nat Rev Cancer 2018; 18: 500-510
- 7 Noble WS. What is a support vector machine?. Nat Biotechnol 2006; 24: 1565-1567
- 8 Breiman L. Random forests. Mach Learn 2001; 45: 5-32
- 9 Zaharchuk G, Gong E, Wintermark M. et al. Deep learning in neuroradiology. Am J Neuroradiol 2018; 39: 1776-1784
- 10 Moraal B, Meier DS, Poppe PA. et al. Subtraction MR images in a multiple sclerosis multicenter clinical trail setting. Radiology 2009; 250: 506-514
- 11 Eichinger P, Wiestler H, Zhang H. et al. A novel imaging technique for better detecting new lesions in multiple sclerosis. J Neurol 2017; 264: 1909-1918
- 12 Eichinger P, Schön S, Pongratz V. et al. Accuracy of unenhanced MRI in the detection of new brain lesions in multiple sclerosis. Radiology 2019; 291: 429-435
- 13 Eichinger P, Hock A, Schön S. et al. Acceleration of Double Inversion Recovery Sequences in Multiple Sclerosis with Compressed Sensing. Invest Radiol 2019; 54: 319-324
- 14 Schmidt P, Gaser C, Arsic M. et al. An automated tool for detection of FLAIR-hyperintense white-matter lesions in Multiple Sclerosis. Neuroimage 2012; 59: 3774-3783
- 15 Danelakis A, Theoharis T, Verganelakis DA. Survey of automated multiple sclerosis lesion segmentation techniques on magnetic resonance imaging. Comput Med Imaging Graph 2018; 70: 83-100
- 16 Li H, Jiang G, Zhang J. et al. Fully convolutional network ensembles for white matter hyperintensities segmentation in MR images. Neuroimage 2018; 183: 650-665
- 17 Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 2015: 234-241
- 18 Gabr RE, Coronado I, Robinson M. et al Brain and lesion segmentation in multiple sclerosis using fully convolutional neural networks: A large-scale study. Mult Scler J 2019; [epub ahead of print]
- 19 Gillies RJ, Kinahan PE, Hricak H. Radiomics: Images are more than pictures, they are data. Radiology 2016; 278: 563-577
- 20 Miller DH, Chard DT, Ciccarelli O. Clinically isolated syndromes. Lancet Neurol 2012; 11: 157-169
- 21 Kuhle J, Disanto G, Dobson R. et al. Conversion from clinically isolated syndrome to multiple sclerosis: A large multicantre study. Mult Scler 2015; 21: 1013-1024
- 22 Comi G, Filippi M, Barkhof F. et al. Effect of early interferon treatment on conversion to definite multiple sclerosis: A randomised study. Lancet 2001; 357: 1576-1582
- 23 Comi G, Martinelli V, Rodegher M. et al. Effect of glatiramer acetate on conversion to clinically definite multiple sclerosis in patients with clinically isolated syndrome (PreCISe study): a randomised, double-blind, placebo-controlled trial. Lancet 2009; 374: 1503-1511
- 24 Zhang H, Alberts E, Pongratz V. et al. Predicting conversion from clinically isolated syndrome to multiple sclerosis–An imaging-based machine learning approach. NeuroImage Clin 2019; 21: 101593
- 25 Bendfeldt K, Taschler B, Gaetano L. et al. MRI-based prediction of conversion from clinically isolated syndrome to clinically definite multiple sclerosis using SVM and lesion geometry. Brain Imaging Behav 2019; 13: 1361-1374
- 26 Tallantyre EC, Brookes MJ, Dixon JE. et al. Demonstrating the perivascular distribution of ms lesions in vivo with 7-tesla MRI. Neurology 2008; 70: 2076-2078
- 27 Wottschel V, Chard DT, Enzinger C. et al. SVM recursive feature elimination analyses of structural brain MRI predicts near-term relapses in patients with clinically isolated syndromes suggestive of multiple sclerosis. NeuroImage Clin 2019; 24
- 28 Ma X, Zhang L, Huang D. et al. Quantitative radiomic biomarkers for discrimination between neuromyelitis optica spectrum disorder and multiple sclerosis. J Magn Reson Imaging 2019; 49: 1113-1121
- 29 Liu Y, Dong D, Zhang L. et al. Radiomics in multiple sclerosis and neuromyelitis optica spectrum disorder. Eur Radiol 2019; 29: 4670-4677
- 30 Eshaghi A, Wottschel V, Cortese R. et al. Gray matter MRI differentiates neuromyelitis optica from multiple sclerosis using random forest. Neurology 2016; 87: 2463-2470
- 31 Yoo Y, Tang LYW, Brosch T. et al. Deep learning of joint myelin and T1w MRI features in normal-appearing brain tissue to distinguish between multiple sclerosis patients and healthy controls. NeuroImage Clin 2018; 17: 169-178
- 32 Zhang YD, Pan C, Sun J. et al. Multiple sclerosis identification by convolutional neural network with dropout and parametric ReLU. J Comput Sci 2018; 28: 1-10
- 33 Wang SH, Tang C, Sun J. et al. Multiple sclerosis identification by 14-layer convolutional neural network with batch normalization, dropout, and stochastic pooling. Front Neurosci 2018; 12: 212
- 34 Eitel F, Soehler E, Bellmann-Strobl J. et al. Uncovering convolutional neural network decisions for diagnosing multiple sclerosis on conventional MRI using layer-wise relevance propagation. NeuroImage Clin 2019; 24
- 35 Weygandt M, Hackmack K, Pfüller C. et al. MRI pattern recognition in multiple sclerosis normal-appearing brain areas. PLoS One 2011; 6: e21138
- 36 Hackmack K, Paul F, Weygandt M. et al. Multi-scale classification of disease using structural MRI and wavelet transform. Neuroimage 2012; 62: 48-58
- 37 Hackmack K, Weygandt M, Wuerfel J. et al. Can we overcome the “clinico-radiological paradox” in multiple sclerosis?. J Neurol 2012; 259: 2151-2160
- 38 Li H, Paetzold JC, Sekuboyina A. et al. DiamondGAN: Unified Multi-modal Generative Adversarial Networks for MRI Sequences Synthesis. 2019: 795-803
- 39 Finck T, Li H, Grundl L. et al. Improving Multiple Sclerosis lesion detection with synthetic Double Inversion Recovery images. Invest Radiol 2020;
- 40 Geurts JJG, Pouwels PJW, Uitdehaag BMJ. et al. Intracortical lesions in multiple sclerosis: Improved detection with 3D double inversion-recovery MR imaging. Radiology 2005; 236: 254-260
- 41 Wattjes MP, Lutterbey GG, Gieseke J. et al. Double inversion recovery brain imaging at 3T: Diagnostic value in the detection of multiple sclerosis lesions. Am J Neuroradiol 2007; 28: 54-59
- 42 Seewann A, Kooi EJ, Roosendaal SD. et al. Postmortem verification of MS cortical lesion detection with 3D DIR. Neurology 2012; 78: 302-308
- 43 Pinto Dos Santos D, Hempel JM, Mildenberger P. et al. Structured Reporting in Clinical Routine. RoFo Fortschritte auf dem Gebiet der Rontgenstrahlen und der Bildgeb Verfahren 2019; 191: 33-39
- 44 Cerqueira JJ, Compston DAS, Geraldes R. et al. Time matters in multiple sclerosis: Can early treatment and long-term follow-up ensure everyone benefits from the latest advances in multiple sclerosis?. J Neurol Neurosurg Psychiatry 2018; 89: 844-850
- 45 Kavaliunas A, Manouchehrinia A, Stawiarz L. et al. Importance of early treatment initiation in the clinical course of multiple sclerosis. Mult Scler 2017; 23: 1233-1240
- 46 Tur C, Kalincik T, Oh J. et al. Head-to-head drug comparisons in multiple sclerosis: Urgent action needed. Neurology 2019; 93: 793-809
- 47 Aymerich Martínez F, Hlinkova J, Auger C. et al. Longitudinal study to measure iron deposit in basal ganglia and related structures in patients with clinically isolated syndrome. Mult Scler 2017; 23: 243-244
- 48 McDonald RJ, McDonald JS, Kallmes DF. et al. Intracranial gadolinium deposition after contrast-enhanced MR imaging. Radiology 2015; 275: 772-782
- 49 Gupta A, Al-Dasuqi K, Xia F. et al. The use of noncontrast quantitative MRI to detect gadolinium-enhancing multiple sclerosis brain lesions: A systematic review and meta-analysis. Am J Neuroradiol 2017; 38: 1317-1322
- 50 Kleesiek J, Morshuis JN, Isensee F. et al. Can Virtual Contrast Enhancement in Brain MRI Replace Gadolinium?: A Feasibility Study. Invest Radiol 2019; 54: 653-660
Correspondence
Publication History
Received: 30 December 2019
Accepted: 17 April 2020
Article published online:
08 July 2020
© Georg Thieme Verlag KG
Stuttgart · New York
-
References
- 1 Thompson AJ, Baranzini SE, Geurts J. et al. Multiple sclerosis. Lancet 2018; 391: 1622-1636
- 2 Thompson AJ, Banwell BL, Barkhof F. et al. Diagnosis of multiple sclerosis: 2017 revisions of the McDonald criteria. Lancet Neurol 2018; 17: 162-173
- 3 Kappos L, De Stefano N, Freedman MS. et al. Inclusion of brain volume loss in a revised measure of “no evidence of disease activity” (NEDA-4) in relapsing-remitting multiple sclerosis. Mult Scler 2016; 22: 1297-1305
- 4 Cortese R, Collorone S, Ciccarelli O. et al. Advances in brain imaging in multiple sclerosis. Ther Adv Neurol Disord 2019; 12
- 5 Lecun Y, Bengio Y, Hinton G. Deep learning. Nature 2015; 521: 436-444
- 6 Hosny A, Parmar C, Quackenbush J. et al. Artificial intelligence in radiology. Nat Rev Cancer 2018; 18: 500-510
- 7 Noble WS. What is a support vector machine?. Nat Biotechnol 2006; 24: 1565-1567
- 8 Breiman L. Random forests. Mach Learn 2001; 45: 5-32
- 9 Zaharchuk G, Gong E, Wintermark M. et al. Deep learning in neuroradiology. Am J Neuroradiol 2018; 39: 1776-1784
- 10 Moraal B, Meier DS, Poppe PA. et al. Subtraction MR images in a multiple sclerosis multicenter clinical trail setting. Radiology 2009; 250: 506-514
- 11 Eichinger P, Wiestler H, Zhang H. et al. A novel imaging technique for better detecting new lesions in multiple sclerosis. J Neurol 2017; 264: 1909-1918
- 12 Eichinger P, Schön S, Pongratz V. et al. Accuracy of unenhanced MRI in the detection of new brain lesions in multiple sclerosis. Radiology 2019; 291: 429-435
- 13 Eichinger P, Hock A, Schön S. et al. Acceleration of Double Inversion Recovery Sequences in Multiple Sclerosis with Compressed Sensing. Invest Radiol 2019; 54: 319-324
- 14 Schmidt P, Gaser C, Arsic M. et al. An automated tool for detection of FLAIR-hyperintense white-matter lesions in Multiple Sclerosis. Neuroimage 2012; 59: 3774-3783
- 15 Danelakis A, Theoharis T, Verganelakis DA. Survey of automated multiple sclerosis lesion segmentation techniques on magnetic resonance imaging. Comput Med Imaging Graph 2018; 70: 83-100
- 16 Li H, Jiang G, Zhang J. et al. Fully convolutional network ensembles for white matter hyperintensities segmentation in MR images. Neuroimage 2018; 183: 650-665
- 17 Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 2015: 234-241
- 18 Gabr RE, Coronado I, Robinson M. et al Brain and lesion segmentation in multiple sclerosis using fully convolutional neural networks: A large-scale study. Mult Scler J 2019; [epub ahead of print]
- 19 Gillies RJ, Kinahan PE, Hricak H. Radiomics: Images are more than pictures, they are data. Radiology 2016; 278: 563-577
- 20 Miller DH, Chard DT, Ciccarelli O. Clinically isolated syndromes. Lancet Neurol 2012; 11: 157-169
- 21 Kuhle J, Disanto G, Dobson R. et al. Conversion from clinically isolated syndrome to multiple sclerosis: A large multicantre study. Mult Scler 2015; 21: 1013-1024
- 22 Comi G, Filippi M, Barkhof F. et al. Effect of early interferon treatment on conversion to definite multiple sclerosis: A randomised study. Lancet 2001; 357: 1576-1582
- 23 Comi G, Martinelli V, Rodegher M. et al. Effect of glatiramer acetate on conversion to clinically definite multiple sclerosis in patients with clinically isolated syndrome (PreCISe study): a randomised, double-blind, placebo-controlled trial. Lancet 2009; 374: 1503-1511
- 24 Zhang H, Alberts E, Pongratz V. et al. Predicting conversion from clinically isolated syndrome to multiple sclerosis–An imaging-based machine learning approach. NeuroImage Clin 2019; 21: 101593
- 25 Bendfeldt K, Taschler B, Gaetano L. et al. MRI-based prediction of conversion from clinically isolated syndrome to clinically definite multiple sclerosis using SVM and lesion geometry. Brain Imaging Behav 2019; 13: 1361-1374
- 26 Tallantyre EC, Brookes MJ, Dixon JE. et al. Demonstrating the perivascular distribution of ms lesions in vivo with 7-tesla MRI. Neurology 2008; 70: 2076-2078
- 27 Wottschel V, Chard DT, Enzinger C. et al. SVM recursive feature elimination analyses of structural brain MRI predicts near-term relapses in patients with clinically isolated syndromes suggestive of multiple sclerosis. NeuroImage Clin 2019; 24
- 28 Ma X, Zhang L, Huang D. et al. Quantitative radiomic biomarkers for discrimination between neuromyelitis optica spectrum disorder and multiple sclerosis. J Magn Reson Imaging 2019; 49: 1113-1121
- 29 Liu Y, Dong D, Zhang L. et al. Radiomics in multiple sclerosis and neuromyelitis optica spectrum disorder. Eur Radiol 2019; 29: 4670-4677
- 30 Eshaghi A, Wottschel V, Cortese R. et al. Gray matter MRI differentiates neuromyelitis optica from multiple sclerosis using random forest. Neurology 2016; 87: 2463-2470
- 31 Yoo Y, Tang LYW, Brosch T. et al. Deep learning of joint myelin and T1w MRI features in normal-appearing brain tissue to distinguish between multiple sclerosis patients and healthy controls. NeuroImage Clin 2018; 17: 169-178
- 32 Zhang YD, Pan C, Sun J. et al. Multiple sclerosis identification by convolutional neural network with dropout and parametric ReLU. J Comput Sci 2018; 28: 1-10
- 33 Wang SH, Tang C, Sun J. et al. Multiple sclerosis identification by 14-layer convolutional neural network with batch normalization, dropout, and stochastic pooling. Front Neurosci 2018; 12: 212
- 34 Eitel F, Soehler E, Bellmann-Strobl J. et al. Uncovering convolutional neural network decisions for diagnosing multiple sclerosis on conventional MRI using layer-wise relevance propagation. NeuroImage Clin 2019; 24
- 35 Weygandt M, Hackmack K, Pfüller C. et al. MRI pattern recognition in multiple sclerosis normal-appearing brain areas. PLoS One 2011; 6: e21138
- 36 Hackmack K, Paul F, Weygandt M. et al. Multi-scale classification of disease using structural MRI and wavelet transform. Neuroimage 2012; 62: 48-58
- 37 Hackmack K, Weygandt M, Wuerfel J. et al. Can we overcome the “clinico-radiological paradox” in multiple sclerosis?. J Neurol 2012; 259: 2151-2160
- 38 Li H, Paetzold JC, Sekuboyina A. et al. DiamondGAN: Unified Multi-modal Generative Adversarial Networks for MRI Sequences Synthesis. 2019: 795-803
- 39 Finck T, Li H, Grundl L. et al. Improving Multiple Sclerosis lesion detection with synthetic Double Inversion Recovery images. Invest Radiol 2020;
- 40 Geurts JJG, Pouwels PJW, Uitdehaag BMJ. et al. Intracortical lesions in multiple sclerosis: Improved detection with 3D double inversion-recovery MR imaging. Radiology 2005; 236: 254-260
- 41 Wattjes MP, Lutterbey GG, Gieseke J. et al. Double inversion recovery brain imaging at 3T: Diagnostic value in the detection of multiple sclerosis lesions. Am J Neuroradiol 2007; 28: 54-59
- 42 Seewann A, Kooi EJ, Roosendaal SD. et al. Postmortem verification of MS cortical lesion detection with 3D DIR. Neurology 2012; 78: 302-308
- 43 Pinto Dos Santos D, Hempel JM, Mildenberger P. et al. Structured Reporting in Clinical Routine. RoFo Fortschritte auf dem Gebiet der Rontgenstrahlen und der Bildgeb Verfahren 2019; 191: 33-39
- 44 Cerqueira JJ, Compston DAS, Geraldes R. et al. Time matters in multiple sclerosis: Can early treatment and long-term follow-up ensure everyone benefits from the latest advances in multiple sclerosis?. J Neurol Neurosurg Psychiatry 2018; 89: 844-850
- 45 Kavaliunas A, Manouchehrinia A, Stawiarz L. et al. Importance of early treatment initiation in the clinical course of multiple sclerosis. Mult Scler 2017; 23: 1233-1240
- 46 Tur C, Kalincik T, Oh J. et al. Head-to-head drug comparisons in multiple sclerosis: Urgent action needed. Neurology 2019; 93: 793-809
- 47 Aymerich Martínez F, Hlinkova J, Auger C. et al. Longitudinal study to measure iron deposit in basal ganglia and related structures in patients with clinically isolated syndrome. Mult Scler 2017; 23: 243-244
- 48 McDonald RJ, McDonald JS, Kallmes DF. et al. Intracranial gadolinium deposition after contrast-enhanced MR imaging. Radiology 2015; 275: 772-782
- 49 Gupta A, Al-Dasuqi K, Xia F. et al. The use of noncontrast quantitative MRI to detect gadolinium-enhancing multiple sclerosis brain lesions: A systematic review and meta-analysis. Am J Neuroradiol 2017; 38: 1317-1322
- 50 Kleesiek J, Morshuis JN, Isensee F. et al. Can Virtual Contrast Enhancement in Brain MRI Replace Gadolinium?: A Feasibility Study. Invest Radiol 2019; 54: 653-660