

Subscribe to RSS
DOI: 10.1055/s-0038-1635115
Nutrigenomic Information in the openEHR Data Set
Authors
Address for correspondence
Publication History
23 November 2017
27 January 2018
Publication Date:
28 March 2018 (online)

Abstract
Background The traditional concept of personalized nutrition is based on adapting diets according to individual needs and preferences. Discussions about personalized nutrition have been on since the Human Genome Project, which has sequenced the human genome. Thenceforth, topics such as nutrigenomics have been assessed to help in better understanding the genetic variation influence on the dietary response and association between nutrients and gene expression. Hence, some challenges impaired the understanding about the nowadays important clinical data and about clinical data assumed to be important in the future.
Objective Finding the main clinical statements in the personalized nutrition field (nutrigenomics) to create the future-proof health information system to the openEHR server based on archetypes, as well as a specific nutrigenomic template.
Methods A systematic literature search was conducted in electronic databases such as PubMed. The aim of this systemic review was to list the chief clinical statements and create archetype and templates for openEHR modeling tools, namely, Ocean Archetype Editor and Ocean Template Design.
Results The literature search led to 51 articles; however, just 26 articles were analyzed after all the herein adopted inclusion criteria were assessed. Of these total, 117 clinical statements were identified, as well as 27 archetype-friendly concepts. Our group modeled four new archetypes (waist-to-height ratio, genetic test results, genetic summary, and diet plan) and finally created the specific nutrigenomic template for nutrition care.
Conclusion The archetypes and the specific openEHR template developed in this study gave dieticians and other health professionals an important tool to their nutrigenomic clinical practices, besides a set of nutrigenomic data to clinical research.
Background and Significance
The nutrigenomics nutrition field uses molecular tools to clarify and understand different responses from nutrient intake by individuals and population groups.[1] It is related to the influence from dietary factor (bioactive molecules) and gene interactions that potentially change the gene expression.[2] [3] Hence, the human genome sequencing enabled the emergence of the so-called “personalized nutrition.”[4]
Hesketh[4] defined personalized nutrition as the ability to detect thousands of stable genetic differences occurring in humans and their impact on nutritional sciences. Accordingly, a new vision of nutritional-advice delivery has emerged as a result of it[5]; in other words, it is nowadays consensus that nutrigenomics is the “future of nutrition.”[6] Therefore, some authors suggested that it is necessary to study the particular genotype of an individual to prescribe a correct dietary advice to him/her. Such study would be effective to prevent chronic diseases[2] [4] [7] [8] and to prescribe personalized dietary nutrient-intake recommendations.[9] [10]
Thus, nutrigenomics has used science to encourage the development of a genetic-tests marketing.[11] [12] However, despite the benefits of applying nutrigenomics, some points such as the lack of knowledge presented by health professionals and experts about how to convey the nutrigenomic information remain significant barriers to its use in clinical practices.[13] [14] Although nutrigenomic studies have shown significant benefits,[15] [16] [17] we are aware of its vast field and of points still requiring further investigation.[18] Therefore, genetic data, particularly from the nutritional genomics field, should be collected and stored in medical records to be further used to improve the collection of robust data and to be integrated into clinical practices.[19]
Hence, the electronic health record (EHR) is an essential tool for the aforementioned process, although the nutrition-support content in EHR is yet reported as insufficient and demands significant improvement.[20] The main causes for such results come from the fact that dieticians have not been deeply involved in the EHR modeling process and from the lack of organizational commitment to encourage health professionals to participate in EHR modeling.[21]
Some authors have reported timelessness, availability, completeness, legibility, and accuracy as the benefits from electronic records.[22] [23] [24] Some of the points identified by Beale[25] regarding ideal EHR systems were: providing information and efficient-use interface to reflect multiple hierarchical, biological, and social organization levels; following multilanguage approach; integrating knowledge-bases such as terminologies and clinical guidelines; providing wide geographical availability of a given record to multiple careers and applications; being consent-based—privacy rules on information use (except for emergency access); etc. Hard efforts have been made to address issues concerning EHR modeling and implementation as a way to allow the development of future-proof EHR systems[26] and these efforts have resulted in openEHR, among others.[27]
The openEHR is a community focused on turning physical-form health data into an electronic form and on assuring the universal interoperability of all electronic data. It is mainly focused on EHR and on related systems.[27] This community assumes two framework levels known as reference and archetype models; both used to separate knowledge from information models. Such separation enables reliable clinical–meaning sharing in addition to assure data interoperability.[26] Moreover, openEHR holds part of the data structure used to represent the instanced data named “Archetype.”[28]
Archetype is a computable expression given to a domain content model offset in structured constraint statements based on a reference (information) model.[29] In other words, archetype is a pattern applied to store complete clinical information capable of being interpreted through EHR.[30] It provides specifications from unique concepts such as body mass index and body temperature to complex concepts such as positive family history.[31]
Archetypes allow the creation of a template formed by a directly, locally, and usable definition. This template turns archetypes into a larger structure often corresponding to a screen form, document, report, or message. Templates are used for data construction and validation.[29]
The openEHR archetypes and templates turn clinicians into active openEHR participants. Therefore, health professionals will simultaneously create and improve these tools; consequently, they will influence EHR functioning and patient care quality.
Objective
The aim of this study was to create the future-proof health information system to the openEHR server based on archetypes, as well as a specific nutrigenomic template resulting from a literature review on publications about nutrigenomics.
Methods
The present research was developed based on the following six stages ([Fig. 1]).

Literature Review
A literature search was performed in PubMed database to find articles published in the nutrigenomics field and to identify the main variables (clinical concepts) used in these studies.
The search was based on the following index terms: “nutrigenomics” AND “diet” AND “intervention,” and “nutrigenomics” AND “nutrition.” Studies complying with the following inclusion criteria were included in the research: (1) intervention studies; (2) intervention using nutrient or food; (3) nutrigenomic studies; (4) human studies; (5) English language; (6) studies published in the last 5 years (2013–2017); and (7) original articles ([Table 1]).
|
Article |
Year |
Clinical statements |
|---|---|---|
|
Ortega-Azorín et al[46] |
2012 |
Polymorphism – genotype – Mediterranean diet – age – body weight – BMI – WC – energy intake – total fat - SFA – MUFA – PUFA – carbohydrates – dietary fiber – alcohol – folic acid – PA – fasting blood glucose – cigarette smokers – variants |
|
Lockyer et al[47] |
2012 |
Age – BMI – SBP – DBP - DASH – total fat – TC – SFA – MUFA – PUFA – carbohydrates – DHA – EPA – genotype – energy intake – protein – alcohol – trans fat – vitamin D – n-3–n-6–fiber - sugar |
|
Mottaghi et al[48] |
2012 |
Gene – gene sequence - vitamin A – age – gender - FFQ - BMI – WHr |
|
Farràs et al[49] |
2013 |
SBP – DBP - TG - BMI – SFA - gender – age – BMI – WC – TC – HDL-c – glucose - ox-LDL |
|
Castañer et al[50] |
2013 |
Mediterranean diet – fiber – SFA – MUFA – PUFA – polyphenol – calorie – meal plans - plasma alfa-linolenic acid – glucose – TG – Apo A1–Apo B – gene – age – gender – BMI – WC – ox-LDL – SBP – DBP – TC – HDL-c – CRP – cigarette smokers |
|
Lang et al[51] |
2013 |
EPA – DHA – height – body weight – WC – BMI – FFQ – dietary recalls – n-3–n-6 - PUFA – vit A – vit E – vit C – selenium – total fat intake – polymorphism |
|
Ribeiro et al[52] |
2013 |
CRP - age – β-carotene - SFA – MUFA – PUFA – – vitamin E – genotype – polymorphism – Hg - erythrogram – leukogram – plateletgram – allele – allele frequencies |
|
Al-Ghnaniem Abbadi et al[53] |
2012 |
Folic acid - body weight – height – alcohol – cigarette smokers – FFQ - vitamin B12–polymorphisms – gender – age – BMI – genotype – plasma homocysteine |
|
Kawakami et al[54] |
2013 |
BMI – fasting blood glucose – insulin – alcohol - age – height – body weight –PBF – HbA1c – TG – TC – HDL-c - creatinine – energy intake – protein – fat – carbohydrate – fiber – gene – water volume – meal volume |
|
Konings et al[55] |
2014 |
Resveratrol – gene |
|
Nielsen and El-Sohemy[56] |
2014 |
SNP – energy – sugars – variants – genes – FFQ – vitamin C – genotype – age – sodium |
|
Kang et al[57] |
2014 |
Variant – TG – Apo A-V – fasting blood glucose – 24-hour recall –SQFFQ – body weight – height – BMI – WC – WHr - SBP – DBP – energy – TEE – BMR – PA – SNPs – TC – apo-B – HDL-c – fasting blood glucose – CRP – age – gender – insulin – – energy intake – carbohydrate – protein – fat – dietary fiber – PUFA |
|
Gahete et al[58] |
2014 |
Age – TC – isocaloric diet – protein – carbohydrate – total fat - SFA – MUFA – food diary – FFQ – alfa-tocopherol – ascorbic acid – fiber |
|
Di Renzo et al[59] |
2014 |
Age – BMI – ox-LDL - Mediterranean diet – carbohydrate – protein – calorie – SFA – PUFA – MUFA – body weight – height - WC – HC – SBP - DBP – WHr – intracellular water – extracellular water – bone mineral content – bone mineral density – PBF – body fat mass – TBFat – BMR – gene |
|
Ouellette et al[60] |
2013 |
PUFA – alcohol – body weight – height – BMI – TC – TG – HDL-c – SNPs – gene – gene sequence – gene position – allele frequency – age – apo B – WC – energy – MUFA – PUFA – SFA – carbohydrates - protein – n-3–plasma cholesterol |
|
Goni et al[61] |
2014 |
BMI – body weight – height – WC – HC – WHr – waist to height ratio – PA – FFQ – energy requirements – energy expenditure – phenotype – genotype – polymorphism – variants – protein – body fat mass – energy – carbohydrate – fat – protein |
|
García-Calzón et al[62] |
2015 |
TL – Mediterranean diet – genotype – polymorphism – gene – fragment length polymorphism – SQFFQ – PA – PA questionnaire – gender– age – BMI – WC - dietary intake – energy intake – carbohydrates – fat intake – protein – glycemic load – MUFA – PUFA – stilbenes |
|
Shab-Bidar et al[63] |
2015 |
Vitamin D – age – fasting blood glucose – dietary intake – energy intake – body weight – height – WC – HC – BMI – trunk fat – HbA1c – insulin – genotype – polymorphism – gender – PA |
|
Di Renzo et al[64] |
2015 |
Gene – alcohol – WC – HC – BMI – age – body weight – height – body composition – ox-LDL – PBF – TBBone – polyphenol – atherogenic index – NC – creatinine – glucose – TC – HDL-c – TG – RCP – stilbenes |
|
Hietaranta-Luoma et al[65] |
2014 |
SBP – DBP – Hg – BMI – TC – TG – fasting blood glucose – genotype – SNPs – alcohol – age – gender – PA |
|
Tremblay et al[66] |
2015 |
Age – BMI - n-3 - – SBP – DBP – body weight - HDL-c – CRP – genotype – SNPs – BMI - WC – TC- TG – CRP - myristic acid – palmitic acid – palmitoleic acid – stearic acid – oleic acid – linoleic acid – dihomo-gamma linolenic acid – arachidonic acid – α-linoleic acid – DHA – EPA – n-3–n-6–polymorphism – gene sequence – gene position – allele frequency |
|
Ahn et al[67] |
2015 |
Body weight – height – LDL-ox – dietary intake – WC – WHr - TC - TG – CRP - apo A-V – SQFFQ – age – gender – BMI – cigarette smoker – alcohol drinker – BMI – SBP – DBP – TG – TC – HDL-c – glucose – insulin – PA |
|
Fallaize et al[68] |
2016 |
Age – gender – PA - phenotype – genotype – FFQ – gene variants – SFA – scoring of polymorphism – genotype – allele frequency – BMI – body weight – WC – height – cholesterol – n-3–fat – SFAs – MUFAs – PUFAs |
|
Mansoori et al[69] |
2015 |
Genotype – polymorphism – DHA– height – WC – gene – age – body weight – BMI – WC – PA – HbA1c – energy intake– carbohydrate – protein – dietary fat – SFA – MUFA – PUFA - fiber – fasting blood glucose – insulin – body fat mass - PBF - visceral fat – trunk fat mass – fat free mass – adiponectin |
|
Pu et al[70] |
2016 |
WC – HDL-c – glucose – SFA – MUFA – PUFA – SNP – BMI – age – TC – HCL-c – body weight – SBP – DBP – gene – alleles – genotype – n-3–n-6 |
|
De Lorenzo et al[71] |
2017 |
PBF – TBFat – body fat mass – LDL-ox – genes – BMI – energy – calories – proteins – carbohydrates – fats – dietary fiber – age – height – body weight – glucose – TC – HDL –c – TG |
Abbreviations: BMI, body mass index; BMR, basal metabolic rate; CRP, C reactive protein; DASH, Dietary Approaches to stop Hypertension; DBP, diastolic blood pressure; DHA, docosahexaenoic acid; EPA, eicosapentaenoic acid; FFQ, Food frequency questionnaire; HC, hip circumference; HDL, high-density lipoprotein; Hg, hemoglobin; LDL, low-density lipoprotein; MUFA, monounsaturated fatty acid; NC, neck circumference; PA, physical activity; PBF, percentage of body fat/total body fat percentage; PUFA, polyunsaturated fatty acid; SBP, systolic blood pressure; SFA, saturated fatty acid; SNP, single-nucleotide polymorphism; SQFFQ, semiquantitative food frequency questionnaire; SUFA, saturated fatty-acid; TBBone, total body bone; TBFat, total body fat; TC, total cholesterol; TEE, total energy expenditure; TG, triglycerides; TL, telomere length; WC, waist circumference; WHr, waist–hip ratio.
Archetype-Friendly Concept Identification
Bacelar et al were the references followed at this step.[32] Our team created a list of clinical concepts, which compose a clinical statement defined as the minimal indivisible information unit to be record by clinicians[33] and of organized clinical statements classified according to the nature of the statement. These concepts were identified in the “methods” and “result” section of each study; moreover, we used all the variables taken into consideration in the studies. Statistical methods were not used to analyze the clinical statements; content was manually interpreted according to team expertise by assessing whether the clinical statements could be model for an archetype.
We organized clinical statements in a structured form after listing them and gathered possible archetype-friendly concepts, mainly those considered objectives and the ones similar to them. We can cite an example to better describe how the clinical statements were assessed. A study presented variables such as “carbohydrate,” “dietary fat,” “polymorphism,” “vitamin C,” and “vitamin D,” and these concepts were gathered into archetype-friendly concepts. Thus, clinical concepts such as vitamin C and D were grouped as “micronutrient” (which is a possible archetype proposition); “carbohydrate” and “dietary fat” were added as “macronutrient” (which is another archetype proposition).
Clinical Knowledge Manager Analysis
The Clinical Knowledge Manager (CKM) is an international clinical-knowledge resource repository that supports international domain knowledge governance,[2] [5] besides being a library of openEHR archetypes and templates. We searched for all archetype-friendly concepts in the repository, because CKM avoids archetype duplication; however, it was necessary to include the concept name and core data items in it. Archetype concepts lacking availability in the CKM were created by the authors.
Archetype Modeling in openEHR
It is hard for developers to perform archetype modeling processes,[26] but we used the Ocean Archetype Editor Software, which is available at the openEHR Web site, to model the archetypes.[31] Classifying the archetypes in entries such as observation, evaluations, instructions, or actions is the first step to model them. Entry types are responsible for solving medical problems such as diseases healed through medication prescription (action) or through symptom observation.[34] Each entry presents specific structure in clinical recording processes; for instance, observation entry holds classes such as concept description, purpose, use, misuse, data (main clinical statements), events (moments when the collected data become important), protocol (information about data collection), and state (details about the patient at the time to get the data). On the other hand, the instruction entry presents classes such as concept description, purpose, use, misuse activities, and protocol.[35] The archetype must be containing complete information, thus, the authors researched for information in journals, papers, books, and in instruction manuals. Moreover, all rules set for archetype creation were followed by the authors according to specific manuals.[36] Finally, the new archetype was recorded in Archetype Definition Language (ADL), which is a formal language used to express the openEHR archetype.[37]
Clinical Knowledge Manager Subjection to Review
The modeled archetypes were subjected to CKM at the Web site (www.openehr.org/CKM). The authors have created an account in the Web site to submit the archetype. We clicked in “propose new archetype” to upload the file after login in. Then, we added a new resource proposition and a brief description of the new archetype. Our archetypes were included in an area called “open archetype proposals” after the submission, and all CKM editors' doubts and communications were answered in there.
In this moment, openEHR editors assessed whether the suggested archetypes were necessary for the CKM repository. Archetypes were included as “draft” in an incubator or project after their approval. Incubators are spaces used in initial archetype development stages.[34] Finally, the archetypes will be exhaustively reviewed by the international clinical community to be approved and published in the CKM.
Nutrigenomic Template
It was possible to create a specific nutrigenomic template (in which the archetypes were arranged) from the herein created archetypes and from the existing archetypes. The Ocean Template Designer Software was used to generate the template; this tool allowed including archetypes in the template.
It was not necessary to subject the project to the Ethics Committee in this study, since it did not use patients' clinical and demographic data.
Results
Literature Review
The bibliographic search followed predefined strategies and resulted in 51 articles. Of those, 25 articles were excluded after the abstracts were analyzed, because they did not present predefined criteria; therefore, the final sample comprised of 26 articles.
Identifying the Archetype-Friendly Concept
The performed critical analysis led to 117 clinical statements, which are the most used variables in nutrigenomic studies. These statements were represented in 27 possible archetypes.
Clinical Knowledge Manager Analysis
However, of the 27 possible archetypes identified in the CKM search, 23 were available in the international CKM repository, so we modeled four archetypes ([Fig. 2]).
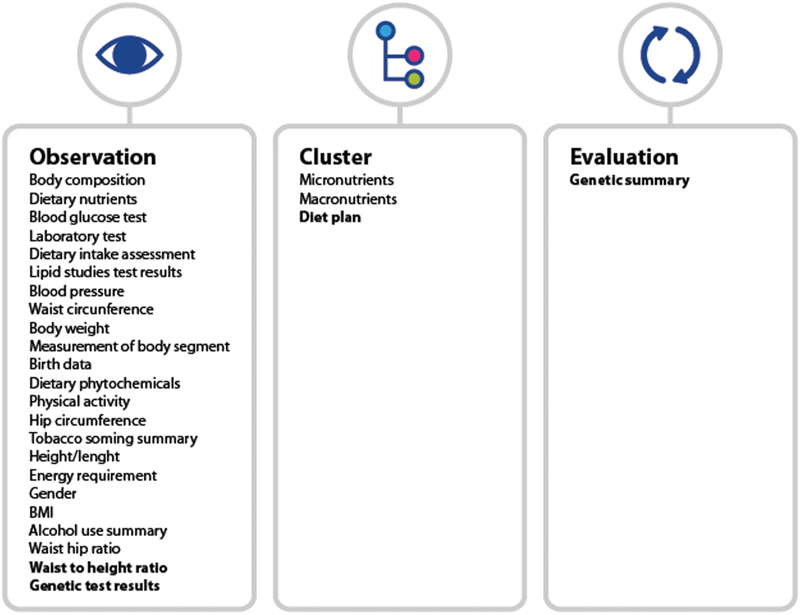
Archetype Modeling in openEHR
Finally, we created four archetypes, namely, waist-to-height ratio, genetic test results, genetic summary, and diet plan, which were subjected to CKM between July and August 2017—except for the “genetic summary,” which was subjected to it in November 2017. The “waist-to-height ratio” archetype was approved (August 2017) for review by editors in the international CKM health community; however, the other archetypes remain under editors' review. All archetypes were created in English language. The purpose of the modeled archetypes was:
-
▪ Waist-to-height ratio (Observation)—Recording waist circumference to height ratio. Mindmap link available at http://www.openehr.org/ckm/-showArchetype_1013.1.2916—Subjected in July and approved for CKM review.
-
▪ Genetic test results (Observation)—Recording results and interpreting individuals' genetic tests. Submitted to and under analysis by the editors. [Fig. 3] represents the proposed archetype.
-
▪ Genetic summary (Evaluation)—Recording summary genetic information about an individuals' genetic details. [Fig. 4] represents the proposed archetype.
-
▪ Diet plan (Cluster)—Recording information about an individual's diet. Submitted to and under analysis by the editors. [Fig. 5] represents the proposed archetype.



A specific nutrigenomic template was created after modeling the four archetypes. [Fig. 6] represents the nutrigenomic template.

Discussion
This article describes the openEHR archetypes and template-based structure development process. It is used to represent clinical concepts from the nutrigenomics field, which assesses the influence from nutrients and bioactive food compounds on the gene expression.[38]
According to modern researchers, nutrigenomics presents significant results. However, registered dieticians (RDs) do not think that such researchers have the basic knowledge to integrate nutrigenomics to their clinical practices.[13] Accordingly, this study becomes relevant to create openEHR archetypes and a specific template capable of providing health professionals with the best information available in the nutrigenomics field.
Our group analyzed the selected articles and identified 117 clinical concepts to the nutrigenomics field, which made it possible to distinguish 27 archetypes. Four archetypes were created from these 27 ones. It is necessary to describe a complete clinical concept to model clinical statements into archetypes; however, the archetype creation process does not follow an established criterion; it is unlimited and depends on the researchers' imagination.[30] Therefore, and because nutrigenomics is rarely used in clinical practices, our group was careful and detailed in the conduction of the experiment performed to create these archetypes. Assembling similar clinical concepts was the number one step in this modeling process, although it is a difficult step, mainly if one takes into account broader fields such as genetics and nutrition.
The American Society for Parenteral and Enteral Nutrition (ASPEN) studied the current situation of the nutrition data found in the EHR by checking the safety and effectiveness of the nutrition documentation.[20] The ASPEN members scored the EHR nutrition component as “fair.” Such grade is possibly associated with the fact that dieticians must be involved in EHR content creation. This result shines the lights on the EHR developer health care system. These ASPEN members reassessed EHR nutrition safety and efficacy 4 years later and reached the same conclusions. However, the authors reinforced that nutrition societies and organizations need to provide education on clinical informatics to their members, as well as templates for standard nutrition care processes.[21]
Thus, it is essential to encourage professional's involvement in openEHR archetype creation, since these archetypes present well-described advantages in the literature.[39] One example is that archetypes can be created and revised, thus making it possible reformulating whenever needed. This is an essential advantage, mainly when it comes to genetic data, because new data are always found and archetypes always need reformulation. The systematic discovery of new syndromes each year is an example of content being needed to be updated mainly because contents and terminologies need to be revised.[40]
Actually, we aimed at creating openEHR archetypes and a specific template to the nutrigenomics field to facilitate EHR use by health professionals and to help storing correct and future-proof contents; however, health care professionals, mainly RD, are not familiar with the nutrigenomics field, and it impairs EHR development.[13] [14]
However, RDs appear to be the most qualified health professionals to talk about nutrigenomics with patients. Accordingly, they must acquire the knowledge and skills necessary to integrate this science to their practices.[13] The present archetypes and template could provide correct information capable of mitigating difficulties and of improving the nutrigenomic care.
Therefore, we have recently modeled nutrition information to prevent and treat childhood obesity based on clinical guideline recommendations.[41] It was possible to herein create 14 new archetype concepts to improve nutrition care. These archetypes can be incorporated to different EHR systems. Other authors have also focused on developing openEHR-based structures to improve clinical care and EHR system in different fields.[31] [32] [42]
Moreover, archetype validation and its publishing is not an easy process. Braun et al proved that creating, validating, and publishing them was a hard work. It is possibly so because of lack of domain expertise and modeling experience, as well as because of the large number of steps to be taken. However, although this is a complicated process, mainly in the genetic field, it is worth emphasizing that it is essential to assure the quality of the medical information model.[31]
The multiplicity of genetic data becomes a challenge at the time to identify the main data and the specific information type to be inserted in EHR. Recently, Mascia et al[39] suggested the following genetic archetypes: “genetic findings” and “sequence variation,” among others. However, the development of the “genetic test results” archetype is in process. In our opinion, some data in this archetype are not related to “results” as “interpretation summary” and “recommendation” data. Besides, the “laboratory identifier” archetype is not enough data to record genetic content and requires “laboratory scope” data to determine whether it is a diagnostic or a research laboratory. Accordingly, in our opinion, the archetype suggested by Mascia et al still presents points to be improved.
Our decision about the clinical genetic statements was to model two archetypes to solve the addressed matter, namely, genetic test results and genetic summary. Our genetic archetypes were based on Marsolo and Spooner,[40] who identified the points needed in genomic EHR, namely, genetic information stored as structured data; data interoperability; phenotypic information stored as structured data and associated with relevant genetic information; data availability for use by rule-based decision-support engines; and EHR use to display the information needed by clinicians to interpret genotypic and phenotypic data.
However, we faced important challenges to model the genetic archetypes:
-
Genetic protocol: The stored genetic information does not follow any standard protocol[43]; although the Electronic Medical Records and Genomics (eMERGE) Network comprise researchers presenting a wide range of expertise in genomics, clinical informatics medicine, statistics, ethics, etc. to develop the best practice for EHR use as genomic tool.[44] We used guideline recommendations and articles that described the minimum genetic EHR requirements to solve this problem.[40] [45]
-
Extensive genetic data: Stored genetic data are extensive and complex; EHR is able to save all genome data. It is possible to include extensive data in openEHR by the electronic path and can be added to archetype, making possible that all the EHR content be genetic data.
-
EHR categories: Much of the EHR content is collected in free text notes, and it increases data variability; therefore, only the indispensable contents were created in free text notes.
We aim to have health professionals presenting good quality nutrition and genetic data, and to have archetypes presenting all the current important data, as well as data that may be essential in the future. A specific nutrigenomic template was developed from archetype creation; however, the new template can be built from our archetypes, as well as from archetypes available at CKM, and meet health professionals' demands.
Limitations
Results in this article reported the archetypes developed through nutrigenomic clinical statements based on literature review. However, it is worth knowing health professional's opinion about the main clinical statements used in nutrigenomic clinical practices. Moreover, many nutrition professionals lack knowledge about this field, and it justifies the difficulty we had to get specialized opinions.
Finally, not all the herein suggested archetypes were approved for review by CKM editors. We know that archetype validation is a hard process in CKM, but we believe that all archetypes built by us are essential to clinical practices; therefore, they will soon be approved.
Conclusion
This article describes the process to create new openEHR archetypes and a specific template based on the literature review. Hence, the new archetypes and the template can be incorporated to different EHR systems and help health professionals in nutrigenomic data collection to improve their clinical practices. The most significant result concerned the fact that all health professionals will have complete nutrigenomic data in the EHR system; these data can be used in further clinical research. We reinforce the importance of having health and information technology (IT) professionals involved in EHR creation, because it would result in a complete and structured EHR system.
Clinical Relevance Statement
The openEHR archetype modeled to EHR (in a specific field) is an important point to improve health care. It contains complete and structured data capable of minimizing data collection errors and of improving the quality of the collected data. Therefore, archetype creation is of significant importance when it comes to providing the best care to patients.
Multiple Choice Question
Archetype creation is linked to design principles; thus, is it possible to say that a correct archetype design principle concerns is:
-
Archetypes used to define aggregates of information suitable for particular local uses.
-
Archetypes that do not create new constraints to the data they refer to.
-
An archetype that cannot be a specialization of another archetype.
-
An archetype that defines constraints to the structure of instances from a reference model.
Correct Answer: The correct answer is option d, there are 14 archetype design principles. According to the “Archetype Definitions and Principles,” letters A and B are wrong, because they are related to a template design used to define aggregates of archetypes suitable for “particular uses,” and to “templates that cannot create new constraints to the archetypes they refer to; they can only further constrain in a compatible way. Letter C is wrong because the archetype can be a specialization of another archetype. Archetypes can be defined at higher or lower detail levels at a given ontological level. Thus, a “biochemistry result” archetype would define the general shape and constraints to all the biochemistry results, whereas a “cholesterol result” archetype could be defined as a specialization of it, to further constrain data to only comply the shape of a cholesterol test.
Conflict of Interest
None.
Acknowledgments
The authors would like to acknowledge–Project “NORTE-01-0145-FEDER-000016” (NanoSTIMA) is financed by the North Portugal Regional Operational Program (NORTE2020), under the PORTUGAL 2020 Partnership Agreement, and through the European Regional Development Fund (ERDF).
Protection of Human and Animal Subjects
Not required.
-
References
- 1 Sales NM, Pelegrini PB, Goersch MC. Nutrigenomics: definitions and advances of this new science. J Nutr Metab 2014; 2014: 202759
- 2 Joffe YT, Houghton CA. A novel approach to the nutrigenetics and nutrigenomics of obesity and weight management. Curr Oncol Rep 2016; 18 (07) 43
- 3 Sebat J, Lakshmi B, Troge J. , et al. Large-scale copy number polymorphism in the human genome. Science 2004; 305 (5683): 525-528
- 4 Hesketh J. Personalised nutrition: how far has nutrigenomics progressed?. Eur J Clin Nutr 2013; 67 (05) 430-435
- 5 Ferguson LR, De Caterina R, Görman U. , et al. Guide and position of the International Society of Nutrigenetics/Nutrigenomics on Personalised Nutrition: part 1—fields of precision nutrition. J Nutrigenet Nutrigenomics 2016; 9 (01) 12-27
- 6 Massoud M, Ragozin H, Schmid G, Spalding L. The Future of Nutrition: Consumers Engage with Science. Palo Alto, CA: Institute for the Future; 2001
- 7 Ferguson JF, Allayee H, Gerszten RE. , et al; American Heart Association Council on Functional Genomics and Translational Biology, Council on Epidemiology and Prevention, and Stroke Council. Nutrigenomics, the microbiome, and gene-environment interactions: new directions in cardiovascular disease research, prevention, and treatment: a scientific statement from the American Heart Association. Circ Cardiovasc Genet 2016; 9 (03) 291-313
- 8 Peña-Romero AC, Navas-Carrillo D, Marín F, Orenes-Piñero E. The future of nutrition: nutrigenomics and nutrigenetics in obesity and cardiovascular diseases. Crit Rev Food Sci Nutr 2017;
- 9 Boushey CJ, Beresford SA, Omenn GS, Motulsky AG. A quantitative assessment of plasma homocysteine as a risk factor for vascular disease. Probable benefits of increasing folic acid intakes. JAMA 1995; 274 (13) 1049-1057
- 10 Ashfield-Watt PA, Pullin CH, Whiting JM. , et al. Methylenetetrahydrofolate reductase 677C-->T genotype modulates homocysteine responses to a folate-rich diet or a low-dose folic acid supplement: a randomized controlled trial. Am J Clin Nutr 2002; 76 (01) 180-186
- 11 Sterling R. The on-line promotion and sale of nutrigenomic services. Genet Med 2008; 10 (11) 784-796
- 12 Goddard KA, Robitaille J, Dowling NF. , et al. Health-related direct-to-consumer genetic tests: a public health assessment and analysis of practices related to Internet-based tests for risk of thrombosis. Public Health Genomics 2009; 12 (02) 92-104
- 13 Cormier H, Tremblay BL, Paradis AM. , et al. Nutrigenomics - perspectives from registered dietitians: a report from the Quebec-wide e-consultation on nutrigenomics among registered dietitians. J Hum Nutr Diet 2014; 27 (04) 391-400
- 14 Rosen R, Earthman C, Marquart L, Reicks M. Continuing education needs of registered dietitians regarding nutrigenomics. J Am Diet Assoc 2006; 106 (08) 1242-1245
- 15 Leung WC, Hessel S, Méplan C. , et al. Two common single nucleotide polymorphisms in the gene encoding beta-carotene 15,15′-monoxygenase alter beta-carotene metabolism in female volunteers. FASEB J 2009; 23 (04) 1041-1053
- 16 Haggarty P. B-vitamins, genotype and disease causality. Proc Nutr Soc 2007; 66 (04) 539-547
- 17 Goni L, Cuervo M, Milagro FI, Martínez JA. Future perspectives of personalized weight loss interventions based on nutrigenetic, epigenetic, and metagenomic data. J Nutr 2016; jn218354
- 18 Pavlidis C, Lanara Z, Balasopoulou A, Nebel JC, Katsila T, Patrinos GP. Meta-analysis of genes in commercially available nutrigenomic tests denotes lack of association with dietary intake and nutrient-related pathologies. OMICS 2015; 19 (09) 512-520
- 19 Castle D, DeBusk R. The electronic health record, genetic information, and patient privacy. J Am Diet Assoc 2008; 108 (08) 1372-1374
- 20 Vanek VW. Providing nutrition support in the electronic health record era: the good, the bad, and the ugly. Nutr Clin Pract 2012; 27 (06) 718-737
- 21 Vanek VW, Ayers P, Charney P. , et al. Follow-up survey on functionality of nutrition documentation and ordering nutrition therapy in currently available electronic health record systems. Nutr Clin Pract 2016; 31 (03) 401-415
- 22 McDonald CJ. The barriers to electronic medical record systems and how to overcome them. J Am Med Inform Assoc 1997; 4 (03) 213-221
- 23 Delpierre C, Cuzin L, Fillaux J, Alvarez M, Massip P, Lang T. A systematic review of computer-based patient record systems and quality of care: more randomized clinical trials or a broader approach?. Int J Qual Health Care 2004; 16 (05) 407-416
- 24 Goetz Goldberg D, Kuzel AJ, Feng LB, DeShazo JP, Love LE. EHRs in primary care practices: benefits, challenges, and successful strategies. Am J Manag Care 2012; 18 (02) e48-e54
- 25 Beale T. Archetypes and the EHR. In: Blobel BGME, Pharow P. , eds. Advanced Health Telematics and Telemedicine: The Magdeburg Expert Summit Textbook. Amsterdam: IOS Press; 2003
- 26 Wang L, Min L, Wang R, Lu X, Duan H. Archetype relational mapping - a practical openEHR persistence solution. BMC Med Inform Decis Mak 2015; 15: 88
- 27 openEHR Foundation: openEHR. An open domain-driven platform for developing flexible e-health systems. Welcome to openEHR - Homepage. Available at: http://www.openehr.org/ . Accessed August 13, 2017
- 28 Beale SH, Kalra D, Lloyd D, Schloeffel P. Introducing openEHR. In: openEHR; 2006
- 29 openEHR Foundation. Archetype Definitions and Principles: openEHR Release 1.0.1. London: Revision:1.0; 2007
- 30 Leslie H, Heard S. Archetypes 101. Health Informatics Conference, Sydney, Australia, 2006. Available at: http://www.oceaninformatics.biz/ocean-informatics-resources/ocean-documentation/Conference-Papers.htm
- 31 Braun M, Brandt AU, Schulz S, Boeker M. Validating archetypes for the Multiple Sclerosis Functional Composite. BMC Med Inform Decis Mak 2014; 14: 64
- 32 Gustavo M, Bacelar-Silva RC, Cruz-Correia RJ. From clinical guideline to openEHR: converting JNC7 into archetypes and template. XIII Congresso Brasileiro em Informática em Saúde – CBIS ; 2012: 1-6
- 33 openEHR foundation. EHR Information Model. Release 1.0.2. London, August 2008
- 34 openEHR Foundation: Clinical knowledge manager. Available at: http://www.openehr.org/ckm . Accessed August 21, 2017
- 35 Marcos M, Martínez-Salvador B. Towards the interoperability of computerised guidelines and electronic health records: an experiment with openEHR archetypes and a chronic heart failure guideline. In: Riaño D, ten Teije A, Miksch S, Peleg M. , eds. Knowledge Representation for Health-Care: ECAI 2010 Workshop KR4HC 2010, Lisbon, Portugal, August 17, 2010, Revised Selected Papers. Berlin, Heidelberg: Springer Berlin Heidelberg; 2011: 101-113
- 36 Bacelar-Silva G, Cruz-Correia R. Manual de introdução à norma openEHR, 2015. Available at: www.openehr.academy
- 37 Archetype Definitions and Principles. OpenEHR Release 1.0.1. London: Revision: 1.0; 2007
- 38 German JB, Zivkovic AM, Dallas DC, Smilowitz JT. Nutrigenomics and personalized diets: what will they mean for food?. Annu Rev Food Sci Technol 2011; 2: 97-123
- 39 Mascia C, Uva P, Leo S, Zanetti G. OpenEHR modeling for genomics in clinical practice. bioRxiv; 2017. Available at: https://www.biorxiv.org/content/early/2017/09/28/194720
- 40 Marsolo K, Spooner SA. Clinical genomics in the world of the electronic health record. Genet Med 2013; 15 (10) 786-791
- 41 Priscila Maranhão GB, Gonçalves D, Vieira-Marques P, Cruz-Correia RJ. Relevant lifelong nutrition information for the prevention and treatment of childhood obesity - design and creation of new openEHR archetype set. IEEE International Symposium on Computer-Based Medical Systems: 23/06/2017. Greece; 2017
- 42 Spigolon DN, Moro CM. Essential data sets archetypes for nursing care of endometriosis patients. Rev Gaúcha Enferm 2012; 33 (04) 22-33
- 43 Bosca D, Marco L, Burriel V. , et al. Genetic testing information standardization in HL7 CDA and ISO13606. Stud Health Technol Inform 2013; 192: 338-342
- 44 Electronic Medical Records and Genomics (eMERGE) Network. Available at: https://www.genome.gov/27540473/electronic-medical-records-and-genomics-emerge-network/ . Accessed October 20, 2017
- 45 Claustres M, Kožich V, Dequeker E. , et al; European Society of Human Genetics. Recommendations for reporting results of diagnostic genetic testing (biochemical, cytogenetic and molecular genetic). Eur J Hum Genet 2014; 22 (02) 160-170
- 46 Ortega-Azorín C, Sorlí JV, Asensio EM. , et al. Associations of the FTO rs9939609 and the MC4R rs17782313 polymorphisms with type 2 diabetes are modulated by diet, being higher when adherence to the Mediterranean diet pattern is low. Cardiovasc Diabetol 2012; 11: 137
- 47 Lockyer S, Tzanetou M, Carvalho-Wells AL, Jackson KG, Minihane AM, Lovegrove JA. SATgenε dietary model to implement diets of differing fat composition in prospectively genotyped groups (apoE) using commercially available foods. Br J Nutr 2012; 108 (09) 1705-1713
- 48 Mottaghi A, Salehi E, Keshvarz A, Sezavar H, Saboor-Yaraghi AA. The influence of vitamin A supplementation on Foxp3 and TGF-β gene expression in atherosclerotic patients. J Nutrigenet Nutrigenomics 2012; 5 (06) 314-326
- 49 Farràs M, Valls RM, Fernández-Castillejo S. , et al. Olive oil polyphenols enhance the expression of cholesterol efflux related genes in vivo in humans. A randomized controlled trial. J Nutr Biochem 2013; 24 (07) 1334-1339
- 50 Castañer O, Corella D, Covas MI. , et al; PREDIMED study investigators. In vivo transcriptomic profile after a Mediterranean diet in high-cardiovascular risk patients: a randomized controlled trial. Am J Clin Nutr 2013; 98 (03) 845-853
- 51 Lang JE, Mougey EB, Allayee H. , et al; Nemours Network for Asthma Research. Nutrigenetic response to omega-3 fatty acids in obese asthmatics (NOOA): rationale and methods. Contemp Clin Trials 2013; 34 (02) 326-335
- 52 Ribeiro IF, Miranda-Vilela AL, Klautau-Guimarães MdeN, Grisolia CK. The influence of erythropoietin (EPO T → G) and α-actinin-3 (ACTN3 R577X) polymorphisms on runners' responses to the dietary ingestion of antioxidant supplementation based on pequi oil ( Caryocar brasiliense Camb.): a before-after study. J Nutrigenet Nutrigenomics 2013; 6 (06) 283-304
- 53 Al-Ghnaniem Abbadi R, Emery P, Pufulete M. Short-term folate supplementation in physiological doses has no effect on ESR1 and MLH1 methylation in colonic mucosa of individuals with adenoma. J Nutrigenet Nutrigenomics 2012; 5 (06) 327-338
- 54 Kawakami Y, Yamanaka-Okumura H, Sakuma M. , et al. Gene expression profiling in peripheral white blood cells in response to the intake of food with different glycemic index using a DNA microarray. J Nutrigenet Nutrigenomics 2013; 6 (03) 154-168
- 55 Konings E, Timmers S, Boekschoten MV. , et al. The effects of 30 days resveratrol supplementation on adipose tissue morphology and gene expression patterns in obese men. Int J Obes 2014; 38 (03) 470-473
- 56 Nielsen DE, El-Sohemy A. Disclosure of genetic information and change in dietary intake: a randomized controlled trial. PLoS One 2014; 9 (11) e112665
- 57 Kang R, Kim M, Chae JS, Lee SH, Lee JH. Consumption of whole grains and legumes modulates the genetic effect of the APOA5 -1131C variant on changes in triglyceride and apolipoprotein A-V concentrations in patients with impaired fasting glucose or newly diagnosed type 2 diabetes. Trials 2014; 15: 100
- 58 Gahete MD, Luque RM, Yubero-Serrano EM. , et al. Dietary fat alters the expression of cortistatin and ghrelin systems in the PBMCs of elderly subjects: putative implications in the postprandial inflammatory response. Mol Nutr Food Res 2014; 58 (09) 1897-1906
- 59 Di Renzo L, Carraro A, Valente R, Iacopino L, Colica C, De Lorenzo A. Intake of red wine in different meals modulates oxidized LDL level, oxidative and inflammatory gene expression in healthy people: a randomized crossover trial. Oxid Med Cell Longev 2014; 2014: 681318
- 60 Ouellette C, Cormier H, Rudkowska I. , et al. Polymorphisms in genes involved in the triglyceride synthesis pathway and marine omega-3 polyunsaturated fatty acid supplementation modulate plasma triglyceride levels. J Nutrigenet Nutrigenomics 2013; 6 (4-5): 268-280
- 61 Goni L, Cuervo M, Milagro FI, Martínez JA. Gene-gene interplay and gene-diet interactions involving the MTNR1B rs10830963 variant with body weight loss. J Nutrigenet Nutrigenomics 2014; 7 (4-6): 232-242
- 62 García-Calzón S, Martínez-González MA, Razquin C. , et al. Pro12Ala polymorphism of the PPARγ2 gene interacts with a Mediterranean diet to prevent telomere shortening in the PREDIMED-NAVARRA randomized trial. Circ Cardiovasc Genet 2015; 8 (01) 91-99
- 63 Shab-Bidar S, Neyestani TR, Djazayery A. Vitamin D receptor Cdx-2-dependent response of central obesity to vitamin D intake in the subjects with type 2 diabetes: a randomised clinical trial. Br J Nutr 2015; 114 (09) 1375-1384
- 64 Di Renzo L, Marsella LT, Carraro A. , et al. Changes in LDL oxidative status and oxidative and inflammatory gene expression after red wine intake in healthy people: a randomized trial. Mediators Inflamm 2015; 2015: 317348
- 65 Hietaranta-Luoma HL, Tahvonen R, Iso-Touru T, Puolijoki H, Hopia A. An intervention study of individual, apoE genotype-based dietary and physical-activity advice: impact on health behavior. J Nutrigenet Nutrigenomics 2014; 7 (03) 161-174
- 66 Tremblay BL, Rudkowska I, Couture P, Lemieux S, Julien P, Vohl MC. Modulation of C-reactive protein and plasma omega-6 fatty acid levels by phospholipase A2 gene polymorphisms following a 6-week supplementation with fish oil. Prostaglandins Leukot Essent Fatty Acids 2015; 102-103: 37-45
- 67 Ahn HY, Kim M, Chae JS. , et al. Supplementation with two probiotic strains, Lactobacillus curvatus HY7601 and Lactobacillus plantarum KY1032, reduces fasting triglycerides and enhances apolipoprotein A-V levels in non-diabetic subjects with hypertriglyceridemia. Atherosclerosis 2015; 241 (02) 649-656
- 68 Fallaize R, Celis-Morales C, Macready AL. , et al; Food4Me Study. The effect of the apolipoprotein E genotype on response to personalized dietary advice intervention: findings from the Food4Me randomized controlled trial. Am J Clin Nutr 2016; 104 (03) 827-836
- 69 Mansoori A, Sotoudeh G, Djalali M. , et al. Docosahexaenoic acid-rich fish oil supplementation improves body composition without influence of the PPARγ Pro12Ala polymorphism in patients with type 2 diabetes: a randomized, double-blind, placebo-controlled clinical trial. J Nutrigenet Nutrigenomics 2015; 8 (4-6): 195-204
- 70 Pu S, Eck P, Jenkins DJ. , et al. Interactions between dietary oil treatments and genetic variants modulate fatty acid ethanolamides in plasma and body weight composition. Br J Nutr 2016; 115 (06) 1012-1023
- 71 De Lorenzo A, Bernardini S, Gualtieri P. , et al. Mediterranean meal versus Western meal effects on postprandial ox-LDL, oxidative and inflammatory gene expression in healthy subjects: a randomized controlled trial for nutrigenomic approach in cardiometabolic risk. Acta Diabetol 2017; 54 (02) 141-149
Address for correspondence
-
References
- 1 Sales NM, Pelegrini PB, Goersch MC. Nutrigenomics: definitions and advances of this new science. J Nutr Metab 2014; 2014: 202759
- 2 Joffe YT, Houghton CA. A novel approach to the nutrigenetics and nutrigenomics of obesity and weight management. Curr Oncol Rep 2016; 18 (07) 43
- 3 Sebat J, Lakshmi B, Troge J. , et al. Large-scale copy number polymorphism in the human genome. Science 2004; 305 (5683): 525-528
- 4 Hesketh J. Personalised nutrition: how far has nutrigenomics progressed?. Eur J Clin Nutr 2013; 67 (05) 430-435
- 5 Ferguson LR, De Caterina R, Görman U. , et al. Guide and position of the International Society of Nutrigenetics/Nutrigenomics on Personalised Nutrition: part 1—fields of precision nutrition. J Nutrigenet Nutrigenomics 2016; 9 (01) 12-27
- 6 Massoud M, Ragozin H, Schmid G, Spalding L. The Future of Nutrition: Consumers Engage with Science. Palo Alto, CA: Institute for the Future; 2001
- 7 Ferguson JF, Allayee H, Gerszten RE. , et al; American Heart Association Council on Functional Genomics and Translational Biology, Council on Epidemiology and Prevention, and Stroke Council. Nutrigenomics, the microbiome, and gene-environment interactions: new directions in cardiovascular disease research, prevention, and treatment: a scientific statement from the American Heart Association. Circ Cardiovasc Genet 2016; 9 (03) 291-313
- 8 Peña-Romero AC, Navas-Carrillo D, Marín F, Orenes-Piñero E. The future of nutrition: nutrigenomics and nutrigenetics in obesity and cardiovascular diseases. Crit Rev Food Sci Nutr 2017;
- 9 Boushey CJ, Beresford SA, Omenn GS, Motulsky AG. A quantitative assessment of plasma homocysteine as a risk factor for vascular disease. Probable benefits of increasing folic acid intakes. JAMA 1995; 274 (13) 1049-1057
- 10 Ashfield-Watt PA, Pullin CH, Whiting JM. , et al. Methylenetetrahydrofolate reductase 677C-->T genotype modulates homocysteine responses to a folate-rich diet or a low-dose folic acid supplement: a randomized controlled trial. Am J Clin Nutr 2002; 76 (01) 180-186
- 11 Sterling R. The on-line promotion and sale of nutrigenomic services. Genet Med 2008; 10 (11) 784-796
- 12 Goddard KA, Robitaille J, Dowling NF. , et al. Health-related direct-to-consumer genetic tests: a public health assessment and analysis of practices related to Internet-based tests for risk of thrombosis. Public Health Genomics 2009; 12 (02) 92-104
- 13 Cormier H, Tremblay BL, Paradis AM. , et al. Nutrigenomics - perspectives from registered dietitians: a report from the Quebec-wide e-consultation on nutrigenomics among registered dietitians. J Hum Nutr Diet 2014; 27 (04) 391-400
- 14 Rosen R, Earthman C, Marquart L, Reicks M. Continuing education needs of registered dietitians regarding nutrigenomics. J Am Diet Assoc 2006; 106 (08) 1242-1245
- 15 Leung WC, Hessel S, Méplan C. , et al. Two common single nucleotide polymorphisms in the gene encoding beta-carotene 15,15′-monoxygenase alter beta-carotene metabolism in female volunteers. FASEB J 2009; 23 (04) 1041-1053
- 16 Haggarty P. B-vitamins, genotype and disease causality. Proc Nutr Soc 2007; 66 (04) 539-547
- 17 Goni L, Cuervo M, Milagro FI, Martínez JA. Future perspectives of personalized weight loss interventions based on nutrigenetic, epigenetic, and metagenomic data. J Nutr 2016; jn218354
- 18 Pavlidis C, Lanara Z, Balasopoulou A, Nebel JC, Katsila T, Patrinos GP. Meta-analysis of genes in commercially available nutrigenomic tests denotes lack of association with dietary intake and nutrient-related pathologies. OMICS 2015; 19 (09) 512-520
- 19 Castle D, DeBusk R. The electronic health record, genetic information, and patient privacy. J Am Diet Assoc 2008; 108 (08) 1372-1374
- 20 Vanek VW. Providing nutrition support in the electronic health record era: the good, the bad, and the ugly. Nutr Clin Pract 2012; 27 (06) 718-737
- 21 Vanek VW, Ayers P, Charney P. , et al. Follow-up survey on functionality of nutrition documentation and ordering nutrition therapy in currently available electronic health record systems. Nutr Clin Pract 2016; 31 (03) 401-415
- 22 McDonald CJ. The barriers to electronic medical record systems and how to overcome them. J Am Med Inform Assoc 1997; 4 (03) 213-221
- 23 Delpierre C, Cuzin L, Fillaux J, Alvarez M, Massip P, Lang T. A systematic review of computer-based patient record systems and quality of care: more randomized clinical trials or a broader approach?. Int J Qual Health Care 2004; 16 (05) 407-416
- 24 Goetz Goldberg D, Kuzel AJ, Feng LB, DeShazo JP, Love LE. EHRs in primary care practices: benefits, challenges, and successful strategies. Am J Manag Care 2012; 18 (02) e48-e54
- 25 Beale T. Archetypes and the EHR. In: Blobel BGME, Pharow P. , eds. Advanced Health Telematics and Telemedicine: The Magdeburg Expert Summit Textbook. Amsterdam: IOS Press; 2003
- 26 Wang L, Min L, Wang R, Lu X, Duan H. Archetype relational mapping - a practical openEHR persistence solution. BMC Med Inform Decis Mak 2015; 15: 88
- 27 openEHR Foundation: openEHR. An open domain-driven platform for developing flexible e-health systems. Welcome to openEHR - Homepage. Available at: http://www.openehr.org/ . Accessed August 13, 2017
- 28 Beale SH, Kalra D, Lloyd D, Schloeffel P. Introducing openEHR. In: openEHR; 2006
- 29 openEHR Foundation. Archetype Definitions and Principles: openEHR Release 1.0.1. London: Revision:1.0; 2007
- 30 Leslie H, Heard S. Archetypes 101. Health Informatics Conference, Sydney, Australia, 2006. Available at: http://www.oceaninformatics.biz/ocean-informatics-resources/ocean-documentation/Conference-Papers.htm
- 31 Braun M, Brandt AU, Schulz S, Boeker M. Validating archetypes for the Multiple Sclerosis Functional Composite. BMC Med Inform Decis Mak 2014; 14: 64
- 32 Gustavo M, Bacelar-Silva RC, Cruz-Correia RJ. From clinical guideline to openEHR: converting JNC7 into archetypes and template. XIII Congresso Brasileiro em Informática em Saúde – CBIS ; 2012: 1-6
- 33 openEHR foundation. EHR Information Model. Release 1.0.2. London, August 2008
- 34 openEHR Foundation: Clinical knowledge manager. Available at: http://www.openehr.org/ckm . Accessed August 21, 2017
- 35 Marcos M, Martínez-Salvador B. Towards the interoperability of computerised guidelines and electronic health records: an experiment with openEHR archetypes and a chronic heart failure guideline. In: Riaño D, ten Teije A, Miksch S, Peleg M. , eds. Knowledge Representation for Health-Care: ECAI 2010 Workshop KR4HC 2010, Lisbon, Portugal, August 17, 2010, Revised Selected Papers. Berlin, Heidelberg: Springer Berlin Heidelberg; 2011: 101-113
- 36 Bacelar-Silva G, Cruz-Correia R. Manual de introdução à norma openEHR, 2015. Available at: www.openehr.academy
- 37 Archetype Definitions and Principles. OpenEHR Release 1.0.1. London: Revision: 1.0; 2007
- 38 German JB, Zivkovic AM, Dallas DC, Smilowitz JT. Nutrigenomics and personalized diets: what will they mean for food?. Annu Rev Food Sci Technol 2011; 2: 97-123
- 39 Mascia C, Uva P, Leo S, Zanetti G. OpenEHR modeling for genomics in clinical practice. bioRxiv; 2017. Available at: https://www.biorxiv.org/content/early/2017/09/28/194720
- 40 Marsolo K, Spooner SA. Clinical genomics in the world of the electronic health record. Genet Med 2013; 15 (10) 786-791
- 41 Priscila Maranhão GB, Gonçalves D, Vieira-Marques P, Cruz-Correia RJ. Relevant lifelong nutrition information for the prevention and treatment of childhood obesity - design and creation of new openEHR archetype set. IEEE International Symposium on Computer-Based Medical Systems: 23/06/2017. Greece; 2017
- 42 Spigolon DN, Moro CM. Essential data sets archetypes for nursing care of endometriosis patients. Rev Gaúcha Enferm 2012; 33 (04) 22-33
- 43 Bosca D, Marco L, Burriel V. , et al. Genetic testing information standardization in HL7 CDA and ISO13606. Stud Health Technol Inform 2013; 192: 338-342
- 44 Electronic Medical Records and Genomics (eMERGE) Network. Available at: https://www.genome.gov/27540473/electronic-medical-records-and-genomics-emerge-network/ . Accessed October 20, 2017
- 45 Claustres M, Kožich V, Dequeker E. , et al; European Society of Human Genetics. Recommendations for reporting results of diagnostic genetic testing (biochemical, cytogenetic and molecular genetic). Eur J Hum Genet 2014; 22 (02) 160-170
- 46 Ortega-Azorín C, Sorlí JV, Asensio EM. , et al. Associations of the FTO rs9939609 and the MC4R rs17782313 polymorphisms with type 2 diabetes are modulated by diet, being higher when adherence to the Mediterranean diet pattern is low. Cardiovasc Diabetol 2012; 11: 137
- 47 Lockyer S, Tzanetou M, Carvalho-Wells AL, Jackson KG, Minihane AM, Lovegrove JA. SATgenε dietary model to implement diets of differing fat composition in prospectively genotyped groups (apoE) using commercially available foods. Br J Nutr 2012; 108 (09) 1705-1713
- 48 Mottaghi A, Salehi E, Keshvarz A, Sezavar H, Saboor-Yaraghi AA. The influence of vitamin A supplementation on Foxp3 and TGF-β gene expression in atherosclerotic patients. J Nutrigenet Nutrigenomics 2012; 5 (06) 314-326
- 49 Farràs M, Valls RM, Fernández-Castillejo S. , et al. Olive oil polyphenols enhance the expression of cholesterol efflux related genes in vivo in humans. A randomized controlled trial. J Nutr Biochem 2013; 24 (07) 1334-1339
- 50 Castañer O, Corella D, Covas MI. , et al; PREDIMED study investigators. In vivo transcriptomic profile after a Mediterranean diet in high-cardiovascular risk patients: a randomized controlled trial. Am J Clin Nutr 2013; 98 (03) 845-853
- 51 Lang JE, Mougey EB, Allayee H. , et al; Nemours Network for Asthma Research. Nutrigenetic response to omega-3 fatty acids in obese asthmatics (NOOA): rationale and methods. Contemp Clin Trials 2013; 34 (02) 326-335
- 52 Ribeiro IF, Miranda-Vilela AL, Klautau-Guimarães MdeN, Grisolia CK. The influence of erythropoietin (EPO T → G) and α-actinin-3 (ACTN3 R577X) polymorphisms on runners' responses to the dietary ingestion of antioxidant supplementation based on pequi oil ( Caryocar brasiliense Camb.): a before-after study. J Nutrigenet Nutrigenomics 2013; 6 (06) 283-304
- 53 Al-Ghnaniem Abbadi R, Emery P, Pufulete M. Short-term folate supplementation in physiological doses has no effect on ESR1 and MLH1 methylation in colonic mucosa of individuals with adenoma. J Nutrigenet Nutrigenomics 2012; 5 (06) 327-338
- 54 Kawakami Y, Yamanaka-Okumura H, Sakuma M. , et al. Gene expression profiling in peripheral white blood cells in response to the intake of food with different glycemic index using a DNA microarray. J Nutrigenet Nutrigenomics 2013; 6 (03) 154-168
- 55 Konings E, Timmers S, Boekschoten MV. , et al. The effects of 30 days resveratrol supplementation on adipose tissue morphology and gene expression patterns in obese men. Int J Obes 2014; 38 (03) 470-473
- 56 Nielsen DE, El-Sohemy A. Disclosure of genetic information and change in dietary intake: a randomized controlled trial. PLoS One 2014; 9 (11) e112665
- 57 Kang R, Kim M, Chae JS, Lee SH, Lee JH. Consumption of whole grains and legumes modulates the genetic effect of the APOA5 -1131C variant on changes in triglyceride and apolipoprotein A-V concentrations in patients with impaired fasting glucose or newly diagnosed type 2 diabetes. Trials 2014; 15: 100
- 58 Gahete MD, Luque RM, Yubero-Serrano EM. , et al. Dietary fat alters the expression of cortistatin and ghrelin systems in the PBMCs of elderly subjects: putative implications in the postprandial inflammatory response. Mol Nutr Food Res 2014; 58 (09) 1897-1906
- 59 Di Renzo L, Carraro A, Valente R, Iacopino L, Colica C, De Lorenzo A. Intake of red wine in different meals modulates oxidized LDL level, oxidative and inflammatory gene expression in healthy people: a randomized crossover trial. Oxid Med Cell Longev 2014; 2014: 681318
- 60 Ouellette C, Cormier H, Rudkowska I. , et al. Polymorphisms in genes involved in the triglyceride synthesis pathway and marine omega-3 polyunsaturated fatty acid supplementation modulate plasma triglyceride levels. J Nutrigenet Nutrigenomics 2013; 6 (4-5): 268-280
- 61 Goni L, Cuervo M, Milagro FI, Martínez JA. Gene-gene interplay and gene-diet interactions involving the MTNR1B rs10830963 variant with body weight loss. J Nutrigenet Nutrigenomics 2014; 7 (4-6): 232-242
- 62 García-Calzón S, Martínez-González MA, Razquin C. , et al. Pro12Ala polymorphism of the PPARγ2 gene interacts with a Mediterranean diet to prevent telomere shortening in the PREDIMED-NAVARRA randomized trial. Circ Cardiovasc Genet 2015; 8 (01) 91-99
- 63 Shab-Bidar S, Neyestani TR, Djazayery A. Vitamin D receptor Cdx-2-dependent response of central obesity to vitamin D intake in the subjects with type 2 diabetes: a randomised clinical trial. Br J Nutr 2015; 114 (09) 1375-1384
- 64 Di Renzo L, Marsella LT, Carraro A. , et al. Changes in LDL oxidative status and oxidative and inflammatory gene expression after red wine intake in healthy people: a randomized trial. Mediators Inflamm 2015; 2015: 317348
- 65 Hietaranta-Luoma HL, Tahvonen R, Iso-Touru T, Puolijoki H, Hopia A. An intervention study of individual, apoE genotype-based dietary and physical-activity advice: impact on health behavior. J Nutrigenet Nutrigenomics 2014; 7 (03) 161-174
- 66 Tremblay BL, Rudkowska I, Couture P, Lemieux S, Julien P, Vohl MC. Modulation of C-reactive protein and plasma omega-6 fatty acid levels by phospholipase A2 gene polymorphisms following a 6-week supplementation with fish oil. Prostaglandins Leukot Essent Fatty Acids 2015; 102-103: 37-45
- 67 Ahn HY, Kim M, Chae JS. , et al. Supplementation with two probiotic strains, Lactobacillus curvatus HY7601 and Lactobacillus plantarum KY1032, reduces fasting triglycerides and enhances apolipoprotein A-V levels in non-diabetic subjects with hypertriglyceridemia. Atherosclerosis 2015; 241 (02) 649-656
- 68 Fallaize R, Celis-Morales C, Macready AL. , et al; Food4Me Study. The effect of the apolipoprotein E genotype on response to personalized dietary advice intervention: findings from the Food4Me randomized controlled trial. Am J Clin Nutr 2016; 104 (03) 827-836
- 69 Mansoori A, Sotoudeh G, Djalali M. , et al. Docosahexaenoic acid-rich fish oil supplementation improves body composition without influence of the PPARγ Pro12Ala polymorphism in patients with type 2 diabetes: a randomized, double-blind, placebo-controlled clinical trial. J Nutrigenet Nutrigenomics 2015; 8 (4-6): 195-204
- 70 Pu S, Eck P, Jenkins DJ. , et al. Interactions between dietary oil treatments and genetic variants modulate fatty acid ethanolamides in plasma and body weight composition. Br J Nutr 2016; 115 (06) 1012-1023
- 71 De Lorenzo A, Bernardini S, Gualtieri P. , et al. Mediterranean meal versus Western meal effects on postprandial ox-LDL, oxidative and inflammatory gene expression in healthy subjects: a randomized controlled trial for nutrigenomic approach in cardiometabolic risk. Acta Diabetol 2017; 54 (02) 141-149